- INDEXATION
- INDEXATIONL’indexation consiste à identifier dans un document certains éléments significatifs qui serviront de clé pour retrouver ce document au sein d’une collection. Ces éléments comprennent le nom de l’auteur, le titre de l’ouvrage, le nom de l’éditeur, la date de publication et l’intitulé du sujet traité. Des règles d’usage régissent le choix et la forme des noms, les listes de vedettes matières, les plans de classification et d’analyse documentaire. La programmation et l’impression des index par ordinateur ont accru l’importance de ces codes. La complexité des documents modernes et la variété des formes sous lesquelles ils se présentent exigent qu’on aborde de façon systématique la construction des index et leur emploi.Étymologiquement, indexer signifie montrer du doigt quelque chose qu’on veut identifier à telle ou telle fin. À l’époque moderne, on désigne par ce mot l’action d’identifier tel ou tel aspect significatif de document quelle qu’en soit la nature de façon que cet aspect ou ces aspects servent de clés quand on aura besoin, plus tard, de le rechercher au sein d’une mémoire. Pendant plusieurs siècles, cela s’est appliqué aux livres; l’auteur ou l’éditeur faisaient souvent suivre leur texte d’un index, et les bibliothécaires fournissaient des clés sous forme de listes ou de catalogues indiquant ce que contenaient leurs collections.Notre société a vu se développer l’usage de beaucoup d’autres types de documents, tels que le film sous ses différentes formes, les bandes audio et vidéo, les bandes et disques utilisés comme mémoire dans un ordinateur. Tous ces documents contiennent de l’information, qu’il convient d’étiqueter clairement afin que ceux qui désirent la consulter puissent y accéder aisément.On caractérise le plus clairement et le plus évidemment un texte par le nom de l’auteur (ou des auteurs). Si, pour certaines œuvres anciennes, ce nom n’est pas toujours facile à déterminer, en général, pour la plupart des documents récents, il constitue le premier élément d’information, car il est tout particulièrement commode à identifier. En effet, la page de titre d’un livre donne le nom de l’auteur , nom sous lequel celui-ci veut se faire connaître. Cela est vrai même lorsqu’un document n’est pas l’œuvre d’une seule personne, mais d’une collectivité, une université ou une société de droit privé par exemple. Le titre que l’auteur donne à son œuvre présente les mêmes spécificités.La date et le lieu de publication, l’édition, le nombre de pages, la présence de cartes, de plans, de tables et d’illustrations sont des éléments importants qui aident à identifier un document. Toutes ces caractéristiques sont faciles à déterminer, et l’ensemble du processus porte le nom de catalogage . La disposition des entrées au sein d’un fichier auteurs-titres est relativement simple: noms propres et mots se suivent par ordre alphabétique. Beaucoup de bibliothèques nationales, dont la Bibliothèque nationale française, ont publié des catalogues de leurs collections suivant l’ordre alphabétique des noms d’auteurs, et Les Livres disponibles , le catalogue des livres français disponibles chez les éditeurs, comporte une partie alphabétique par auteurs et une autre par titres, en ordre alphabétique.Le problème de savoir comment choisir l’indexation matières d’un document est beaucoup plus complexe; en général, le titre ne fait guère plus que mettre en relief un ou deux mots importants. On pourrait croire qu’un auteur est le mieux placé pour concevoir l’index matières de son propre livre, mais les éditeurs préfèrent souvent confier la préparation de l’index à des indexeurs professionnels qui connaissent parfaitement la théorie et la pratique de l’indexation matières et de l’analyse documentaire ou de la classification.La classification figure depuis longtemps parmi les outils fondamentaux de la méthode scientifique. Ainsi, pour ordonner de façon systématique l’ensemble des collections d’une bibliothèque, il faut comprendre, en théorie et en pratique, comment sont structurées les connaissances humaines et comment il convient de grouper les documents afin de montrer les relations qu’il y a entre leurs sujets, ce qui aide le lecteur à mieux comprendre le classement et à mieux utiliser la collection. Les experts se penchent depuis plusieurs siècles sur ces activités complexes que sont le catalogage et la classification. Ils ont élaboré un grand nombre de systèmes, de règles et de codes.1. Les règles catalographiquesDepuis l’Antiquité, nombreux et célèbres sont les écrivains qui ont fait remarquer l’intérêt du livre et de l’existence de bibliothèques bien organisées; mais le premier à s’efforcer sérieusement de fournir un guide systématique aux catalogueurs fut Antony Panizzi qui rédigea, en 1839, un ensemble de règles à l’intention des employés de la bibliothèque du British Museum. Pendant le demi-siècle qui suivit, dans plusieurs pays, des bibliothèques nationales ou d’universités ainsi que des sociétés de bibliothécaires l’imitèrent. En 1908, les associations de bibliothécaires britanniques et américaines produisirent ensemble le premier code international. En 1948, l’Association française de normalisation commença à étudier ces codes pour déterminer s’ils conviendraient aux bibliothèques françaises. En 1961, la fédération internationale des associations de bibliothécaires et des bibliothèques (I.F.L.A.) organisa à Paris un congrès international sur les principes de catalogage, auquel participèrent plus de cinquante nations, et presque toutes étaient d’accord sur la nécessité d’une norme internationale. Les «principes de Paris» sont la base de tous les travaux ultérieurs rendus encore plus nécessaires par les progrès des méthodes informatisées de catalogage.Ces méthodes furent introduites essentiellement par la bibliothèque du Congrès des États-Unis avec le projet MARC (Machine Readable Cataloguing, catalogage lisible par machine). Un projet pilote appelé MARC I fut lancé en 1966, et l’expérience acquise dans plusieurs bibliothèques et par la British National Bibliography (Bibliographie nationale britannique) permit de concevoir un format normalisé international, appelé MARC II, qui permet l’échange international de données de catalogage. Bien que l’accord ne soit pas unanime, les bandes MARC britanniques et américaines sont maintenant disponibles par souscription, et dans le monde entier beaucoup de bibliothèques y conforment leur pratique.Encouragée par l’U.N.E.S.C.O., l’I.F.L.A. possède en outre deux programmes d’échanges de données: l’UBC (contrôle bibliographique universel) et l’UAP (accès universel aux publications). Les pays qui participent à ces programmes s’engagent à enregistrer sous forme informatisée toutes leurs publications et à les rendre disponibles grâce à un réseau de fichiers compatibles. Cela est plus facile à réaliser depuis qu’ont été introduites la numérotation ISBN (numéro international normalisé du livre) et la numérotation ISSN (numéro international normalisé de publication en série). Chaque pays possède un bureau national de numérotation ISBN qui attribue à chaque éditeur un certain groupe de chiffres; l’éditeur attribue à chaque livre un numéro unique qui est imprimé comme partie intégrante des données d’édition, ce qui facilite la commande des livres neufs et économise de la place dans les fichiers informatisés.2. L’indexation matièresOn peut dire que la plupart des problèmes techniques de l’indexation par auteur sont à présent résolus, mais c’est loin d’être le cas pour les systèmes d’indexation matières ou de classification. On en parle depuis l’Antiquité, mais le premier philosophe moderne qui ait exercé une influence considérable fut Francis Bacon, dont le système se fondait sur les trois fonctions intellectuelles: la mémoire, l’imagination et la raison. Ce système exerça une profonde influence sur la grande Encyclopédie , comme le reconnaît Diderot dans sa Préface. Gabriel Naudé, bibliothécaire de la Mazarine, déclarait que, pour disposer les livres dans une bibliothèque, le meilleur ordre serait «le plus facile, le moins intrigué, le plus naturel, usité, et qui suit les facultés de théologie, médecine, jurisprudence, histoire, philosophie, mathématiques, humanité». Tous les systèmes ultérieurs se sont fondés sur le principe du «plus facile»; quant au «plus naturel», il opère une synthèse entre l’approche baconienne des facultés mentales et l’approche scolastique des disciplines traditionnelles sur lesquelles sont fondées les universités.L’index auteurs représente un accès facile et naturel aux documents d’une collection, mais l’index matières soulève difficultés et controverses. D’abord, le choix des noms des sujets implique une définition de ceux-ci, or les définitions ne font pas toujours l’objet d’un accord unanime, surtout d’un pays à l’autre; ensuite, les progrès de la connaissance risquent de changer les rapports entre sujets. Les systèmes de classification reflètent les théories de la connaissance en vigueur à leur époque; il peut donc arriver qu’un nouveau système plus satisfaisant rende bientôt périmés les systèmes existants. Pour qu’un système réussisse, il faut qu’il présente un fondement théorique reconnaissable; les utilisateurs s’apercevront ainsi qu’il a un sens pour eux. Les systèmes fondés sur les disciplines universitaires ont un sens parce qu’ils expriment la façon dont leur époque se représente l’organisation des connaissances humaines; mais, en contrepartie, ils n’abordent qu’avec précaution les idées nouvelles. Cette timidité se trouve aggravée dans les bibliothèques parce que le reclassement d’un nombre élevé de documents est une entreprise importante et coûteuse. On est donc tenté de faire figurer les connaissances nouvelles dans des cadres existants; mais après cela il n’est plus ni facile ni naturel d’y accéder. Tel est le problème qui préoccupait Melvil Dewey, dans la chapelle de Amherst College (Massachusetts) en 1873, quand une intuition lui vint à l’esprit: il s’agissait de subdiviser les sujets de façon hiérarchique per genus et differentiam et d’uniformiser le rangement des livres dans les rayons en attribuant à chaque sujet un nombre suivant une notation décimale fractionnaire. Ainsi, l’ordre des documents refléterait la manière dont les savants, notamment dans les «sciences classificatoires», étudiaient leur discipline et y réfléchissaient. La première édition de la classification décimale de Dewey (D.D.C.), en 1876, expose que le système a été conçu pour les besoins du catalogage et de l’indexation, mais qu’on a constaté qu’il servait aussi fort bien à numéroter et à ranger les livres et brochures dans les rayonnages. On a appelé «ordre baconien inversé» l’ordre dans lequel se succèdent les classes: Philosophie, Religion, puis Sciences, Littérature et Arts, Histoire et Géographie. Ce système a connu un succès considérable dans les bibliothèques du monde entier, et un bureau chargé de le réviser dépend de la bibliothèque du Congrès qui, comme la B.N.B. (Bibliographie nationale britannique), incorpore dans ses notices MARC les numéros des classes D.D.C. Un exemple simple illustre la structure de la D.D.C.:
 Chaque terme représente un sous-ensemble du terme précédent, et chaque numéro est une subdivision du numéro précédent. L’emploi de cette notation numérique a joué un rôle clé dans l’adoption de la D.D.C. au niveau international. Le système est presque entièrement fondé sur cette méthode d’analyse, mais Dewey reconnut aussi l’importance de la méthode de synthèse qui en est le complément. Il donna un procédé simple servant à diviser géographiquement et chronologiquement chaque sujet en empruntant des chiffres appropriés à la classe 900, Géographie et Histoire. La division 9 de chaque classe était généralement réservée à cet usage, mais les éditions suivantes introduisirent d’autres procédés de synthèse:
Chaque terme représente un sous-ensemble du terme précédent, et chaque numéro est une subdivision du numéro précédent. L’emploi de cette notation numérique a joué un rôle clé dans l’adoption de la D.D.C. au niveau international. Le système est presque entièrement fondé sur cette méthode d’analyse, mais Dewey reconnut aussi l’importance de la méthode de synthèse qui en est le complément. Il donna un procédé simple servant à diviser géographiquement et chronologiquement chaque sujet en empruntant des chiffres appropriés à la classe 900, Géographie et Histoire. La division 9 de chaque classe était généralement réservée à cet usage, mais les éditions suivantes introduisirent d’autres procédés de synthèse: La D.D.C. acquit bientôt une réputation internationale et, dès 1895, Paul Otlet et Henri La Fontaine avaient fondé à Bruxelles un office international de bibliographie qui avait pour mission de concevoir un index universel des articles de périodiques. Ils avaient adapté la D.D.C. de façon à pouvoir classer avec précision des sujets extrêmement spécifiques; ils conservèrent le cadre général mais introduisirent des symboles non numériques qui servaient à rattacher ensemble diverses parties du système. La «version bruxelloise» de la D.D.C. dépassa vite les dimensions de l’original. Quoique l’index universel ait cessé d’exister après la Première Guerre mondiale, la Fédération internationale de documentation (F.I.D.) continua de travailler à améliorer la classification décimale universelle (C.D.U.), éditée dans un grand nombre de langues. L’usage des symboles synthétiques s’est développé, mais les plus usités sont:
La D.D.C. acquit bientôt une réputation internationale et, dès 1895, Paul Otlet et Henri La Fontaine avaient fondé à Bruxelles un office international de bibliographie qui avait pour mission de concevoir un index universel des articles de périodiques. Ils avaient adapté la D.D.C. de façon à pouvoir classer avec précision des sujets extrêmement spécifiques; ils conservèrent le cadre général mais introduisirent des symboles non numériques qui servaient à rattacher ensemble diverses parties du système. La «version bruxelloise» de la D.D.C. dépassa vite les dimensions de l’original. Quoique l’index universel ait cessé d’exister après la Première Guerre mondiale, la Fédération internationale de documentation (F.I.D.) continua de travailler à améliorer la classification décimale universelle (C.D.U.), éditée dans un grand nombre de langues. L’usage des symboles synthétiques s’est développé, mais les plus usités sont: Il en existe encore d’autres, mais les éditeurs recommandent de ne pas en abuser. Comme ils ne se suivent pas selon un ordre connu ou naturel permettant leur classement, il a fallu expliciter cet aspect non séquentiel; dans un index de très grande dimension, comme celui dont a été dotée la bibliothèque du Science Museum de Londres, la complexité des numéros de classement désignant des sujets très spécialisés devient, pour les usagers, une gêne plutôt qu’une aide.Le principe qui consiste à combiner l’analyse et la synthèse afin de spécifier un sujet, au sein d’un système universel, donne à présent l’impulsion principale aux perfectionnements théoriques et pratiques de l’indexation matières. Plusieurs tables auxiliaires (Auxiliary Schedules) ont été fournies par H. E. Bliss dans un livre Bibliographic Classification , dont J. Mills et le British Classification Research Group (groupe britannique de recherches sur la classification) préparent en ce moment la deuxième édition.Celle-ci et les éditions récentes de la D.D.C. et de la C.D.U. ont toutes été fortement influencées par l’œuvre du bibliothécaire indien S. R. Ranganathan, qui traite de tous les aspects des bibliothèques. Sa théorie de l’«analyse par facettes» (Facet Analysis) rend possible un nouveau système général pour dresser des index par sujet. Son propre système, la C.C. (Colon Classification), n’est pas souvent utilisé, sauf en Inde, mais la théorie qui en est la base a été très largement acceptée et a servi à édifier des systèmes de classement pour beaucoup d’organismes spécialisés.3. L’analyse par facettesAvant la publication de la C.C., les systèmes de classification se fondaient sur le principe de l’analyse: il s’agissait d’énumérer des sujets, simples et complexes, en les disposant autant que possible selon des hiérarchies génériques ou pseudo-génériques, comme celle qui distingue le tout de la partie. Au contraire, dans la C.C., seules les hiérarchies génériques vraies sont énumérées; pour subdiviser davantage, on se sert de termes empruntés à diverses catégories, ou «facettes». Une théorie similaire a été élaborée indépendamment dans d’autres pays. L’idée fondamentale est que les concepts qui font partie d’un domaine de connaissance sont susceptibles d’être analysés et groupés ainsi en diverses catégories de termes clairement définis et distincts les uns des autres. Ranganathan a suggéré que ces catégories pourraient s’apparenter à cinq notions fondamentales: Temps, Espace, Matière, Énergie et ce qu’il appelle Personnalité. À l’intérieur de chaque sujet, il a appelé «facettes» les groupes de termes tirés de ces catégories fondamentales, et dans chaque sujet la notion centrale qui lui donne son identité spécifique constitue sa Personnalité. Un spécialiste doit s’attendre à voir groupés, sous cet aspect, les ouvrages qu’il a produits.Cette notion de Personnalité appliquée à un sujet se rapproche de l’idée centrale de la théorie générale des systèmes élaborée par Ludwig von Bertalanffy et d’autres, en particulier aux États-Unis. La théorie se présente comme une exploration scientifique des idées de Total et de Totalité, entités qui présentent une série de niveaux dont l’organisation est de plus en plus complexe. Elle se donne pour but de formuler des principes généraux pour tous les systèmes, quelles qu’en soient les entités élémentaires et quelles que soient les relations qui unissent celles-ci. Dans la C.C., ces entités sont définies par le terme de Personnalité, leurs relations par celui d’Énergie; les parties et les matériaux dont se compose une entité sont classés sous Matière, et une entité qui, à un certain niveau d’organisation, au sein d’une certaine classe, figure comme Personnalité, peut devenir Matière là où elle n’est qu’un des éléments contribuant à former une entité douée de Personnalité appartenant à un niveau supérieur.Ranganathan a été le premier à utiliser la méthode qui consiste à édifier des systèmes de classification multidimensionnels. La puissance de cette méthode et de celles qui s’y apparentent est bien montrée par le nombre de systèmes spécialisés qui les utilisent. Ils n’ont pas tous défini leurs «facettes» en fonction de cinq catégories fondamentales, telles qu’elles sont rapportées par l’Union française de documentation dans les années quarante et cinquante, et présentées dans l’étude faite par Éric de Groslier pour l’U.N.E.S.C.O. Cette puissance tient à l’intégration de deux facteurs: le modèle traditionnel de hiérarchie générique et le modèle moderne d’un système à mailles, ou réseau. Dans le premier, une espèce est définie par la présence d’une caractéristique générique qui la distingue des autres et conditionne son existence, mais, dans les classifications plus anciennes, telles que la C.D.U., l’application de ce modèle était élargie à toutes les subdivisions d’un sujet, simples ou complexes, sans égard à la relation qui existait en réalité entre le genre et l’espèce. Dans un réseau, les concepts sont énumérés un par un en des séquences distinctes; chaque groupe de concepts provient d’une division selon une et une seule caractéristique. Grâce à cette intégration, on obtient un ensemble de séquences, au lieu d’une seule séquence dans laquelle plusieurs caractéristiques se trouvent confondues, et on peut au gré des besoins ménager des intersections exprimant des relations spécifiques entre tout terme d’une séquence et tout terme d’une autre.Dans la C.C., au sein de la classe J, Agriculture, la facette P contient les noms des récoltes, la facette E les noms des procédés, et le symbole qui sert à combiner deux termes est le deux-points:– J 381 riz– J: 7 action de récolter (procédés de récolte)– J 381: 7 récolte du riz.Une classification introduite en pédologie (science des sols) par B. J. Vickery utilise la même méthode avec un autre jeu de symboles:– 9 (types de sol), 9 IQ (limon rouge)– 5 (actions sur les sols), 5 UB (érosion par le vent)– 9 IQ 5 UB (érosion des limons rouges par le vent).4. SYNTOLL’analyse par facettes fut l’aboutissement d’une longue histoire, celle des systèmes de classification et des index matières dans les bibliothèques; et il a été prouvé que l’analyse catégorielle s’adapte aisément aux systèmes automatisés tels que les enregistrements MARC. Le système appelé SYNTOL (Syntagmatic Organisation Language, langage systématique d’organisation) fut conçu par J.-C. Gardin et ses collègues du C.N.R.S. et de la Maison des sciences de l’homme, avec le soutien de l’Euratom, précisément en tant que modèle général d’un système d’indexation automatique. Il s’appuie sur les théories fondamentales de la structure des langues, notamment celle de F. de Saussure, et donc peut tout aussi bien s’appliquer aux systèmes non automatisés. J.-C. Gardin, en tant qu’archéologue, a été conduit à utiliser l’analyse catégorielle pour identifier les artefacts. Contrairement à la plupart des autres systèmes, il part d’une analyse des relations entre sujets et ne cherche pas à dresser des listes de termes telles qu’on en trouve dans les classifications conventionnelles, mais plutôt à établir un métalangage auquel on puisse relier d’autres systèmes. Il consiste en une ossature linguistique codifiée servant à représenter les données, et en un ensemble d’opérations logiques permettant de stocker les descriptions de documents et de les retrouver.SYNTOL a été l’un des premiers systèmes à expliciter la distinction entre deux modes d’organisation des termes signifiants, le mode sémantique et le mode syntaxique. À l’exemple de Saussure, il utilise les deux adjectifs «paradigmatique» et «syntagmatique» pour exprimer cette distinction. Les relations paradigmatiques sont a priori et existent dans le monde réel; celui des phénomènes, indépendamment de la présence d’aucun énoncé ou document. Elles sont reflétées par la structure des systèmes précoordonnés tels que les classifications ou les listes de vedettes matières. Les relations syntagmatiques sont a posteriori et s’appliquent à des énoncés spécifiques ou à des descriptions spécifiques de documents, comme les énoncés et les descriptions que fournit l’analyse par facettes de la C.C. ou d’autres systèmes similaires. Les tables de la C.C. comportent une seule relation entre genre et espèce, entre partie et tout, entre objet et processus; l’action de classer un document exprime les relations syntagmatiques entre les diverses facettes du sujet de ce document.Au début, SYNTOL ne fut appliqué qu’à un petit nombre de disciplines: la physiologie, la psychologie, la sociologie et l’anthropologie culturelle. Mais il est vrai, comme l’affirment ses auteurs, qu’un système d’analyse documentaire qui réussit dans des disciplines dont le langage est loin d’être standardisé se montrera probablement utile dans les domaines où la terminologie est plus précise. SYNTOL spécifie en outre deux groupes de facettes distincts: Source et Thématiques. Dans Source, les rubriques se réfèrent à des attributs physiques comme la forme, la langue et la date; la facette Thématiques inclut les Êtres (personnes ou groupes), le Thème (catégorie de phénomènes telle que la parenté ou la religion), le Temps (évoque des événements), l’Espace (lieu où se manifestent les personnes ou les événements) et le Mode (la manière générale d’aborder le sujet: historique, critique, etc.). Cette terminologie fait ressortir l’intention qui anime l’analyse, comme dans les catégories fondamentales de Ranganathan, et ce système a influencé une grande partie des recherches ultérieures, en particulier pour l’indexation des objets archéologiques.5. La codification et la notationAfin de pouvoir fixer l’ordre de succession des termes dans un classement ordonné, un système doit posséder un outil supplémentaire: un moyen de notation, c’est-à-dire un ensemble de symboles de codification dont la loi de succession soit déjà familière au public. Les deux ensembles les plus connus sont l’alphabet romain et les chiffres arabes; ils ont chacun un sens qui est toujours le même dans tous les pays. Ainsi, chaque élément d’un de ces ensembles assigne au sujet qui lui a été attribué un rang, une position fixe et déterminée au sein d’une succession. Un système multidimensionnel à facettes a besoin que sa notation possède deux caractéristiques principales: des indicateurs de facette et des indicateurs de terme. Ainsi, dans la C.C., les facettes sont signalées par des signes de ponctuation, dans la science des sols par des chiffres arabes, tandis que les termes sont signalés dans la C.C. par des numéros et dans la science des sols par des lettres. Ces deux systèmes sont indépendants des langues.Certaines expériences ont été menées, dans lesquelles on se servait des lettres de l’alphabet romain pour former des syllabes prononçables (G. Cordonnier, au centre de documentation d’Électricité de France, et D. J. Foskett, au London Education Classification – centre de classification pédagogique de l’agglomération de Londres). En dehors du projet Intercocta de l’U.N.E.S.C.O., ce système n’a guère rencontré d’écho, mais des recherches aux États-Unis suggèrent que de telles «syllabes non signifiantes» améliorent nettement la valeur mnémonique des systèmes d’encodage.6. L’indexation alphabétique matièresUne suite ordonnée de sujets repose sur une conception particulière de l’organisation des connaissances; c’est la manière la plus commode de dresser un index matières, mais il faut qu’il y ait une clef permettant aux usagers d’en comprendre la structure. Cette clef est l’index alphabétique, qui donne le symbole de codification correspondant à chaque terme, de même qu’un dictionnaire donne une définition pour chaque mot. L’alphabet ne constitue pas un système permettant d’organiser les concepts en une structure logique, il permet seulement de ranger les mots et les lettres selon un ordre de succession, une série. Les lettres de l’alphabet sont des signes et non des symboles; une liste alphabétique de mots se présentera dans un ordre différent si on traduit les mots dans une autre langue.Cependant, la disposition alphabétique des sujets au sein d’un index a connu un succès considérable, surtout aux États-Unis, parce qu’elle est la façon la plus commode d’accéder à une série de mots. Le nom qu’on décidera de donner à un sujet peut rencontrer une approbation plus ou moins générale, alors qu’il est plus difficile de s’accorder sur la position qu’on attribuera à un sujet au sein d’une structure logique ou intellectuelle, car l’édification d’une telle structure est un processus beaucoup plus complexe que la simple désignation d’un sujet par un nom. Tout processus de codification, telle qu’une suite ordonnée de sujets, n’aboutit à un résultat utilisable que si le code a une clé, de même que toute serrure exige une clé: la clé fait partie intégrante de l’ensemble fonctionnel, mais à elle seule (sans la serrure) elle ne saurait assurer la fermeture de la porte.En fait, la désignation des sujets exige d’être (dans une certaine mesure) normalisée pour être utilisable de façon assez générale, surtout si la collection ou le fichier des documents sont appelés à être utilisés par le public. Depuis le XIXe siècle, les grandes bibliothèques, certains érudits, certaines institutions publient des listes de vedettes matières, présentées en ordre alphabétique. On parle aussi de catalogues matières. Ces listes répondent à une demande constante, puisque deux des plus populaires, celle de la bibliothèque du Congrès et celle de M. E. Sears, ont atteint respectivement leur neuvième et onzième édition, et que les rubriques de la liste LC (Library of Congress, bibliothèque du Congrès) figurent dans les enregistrements MARC II. Il existe un grand nombre de listes de vedettes matières, souvent appelées maintenant «mots clés» ou «descripteurs»: l’une des plus connues est le MeSH (Medical Subject Headings, vedettes matières médicales) de la Bibliothèque nationale de médecine des États-Unis, car elle est souvent utilisée pour l’indexation dans des systèmes automatisés.Bien que la disposition de ces codes, également appelés «langages descripteurs» (descriptor languages ), se fonde essentiellement sur l’alphabet, ils sont également capables d’exprimer des relations entre les sujets (c’est-à-dire une forme camouflée de classement) au moyen de renvois d’un mot à un autre, parfois à plusieurs autres. Ces renvois sont de deux sortes: «Voir» et «Voir aussi». Un renvoi Voir signifie que le premier terme ne doit pas être utilisé pour l’indexation mais que les entrées dans le fichier figurent sous le second mot, auquel on renvoie. Un renvoi Voir aussi signifie que, outre les entrées faites sous le premier terme, il existe aussi des entrées pertinentes correspondant à des ouvrages sur des sujets connexes, figurant sous les mots auxquels on renvoie:– Histoire (ancienne). Voir aussi Archéologie; Bible; Civilisations (antiques)...in Liste des vedettes matières de Sears .– Personnel des Forces arméesX Personnel militaire– KéfirXU Lait7. L’indexation automatiqueAssez tôt dans l’histoire de l’automatisation, on s’est rendu compte qu’on pourrait se servir de machines pour indexer. Les premiers procédés, qui convenaient particulièrement à des index de petite dimension, utilisaient des fiches sur lesquelles on avait imprimé un quadrillage de perforation. Ces fiches à perforation centrale ou marginale se répartissent en deux types: les fiches par terme, où chaque fiche représente un mot clé, et les fiches par item, où chaque fiche représente un document numéroté. Sur les fiches par terme, on perfore les cases correspondant aux numéros des documents qui traitent du sujet évoqué par le terme. Sur les fiches par item, on perfore les cases correspondant aux divers sujets dont traite le document (item) fiché. Certaines fiches sont destinées à être perforées sur les bords, d’autres dans les cases d’un quadrillage couvrant toute la fiche. Il existe plusieurs façons d’utiliser les fiches pour une recherche; pour les fiches à perforations marginales, on repère le trou correspondant au numéro du sujet recherché, on y enfonce une aiguille qui embroche toutes les fiches, et on soulève le paquet: on voit alors tomber les fiches où ce trou a été découpé. Ces procédés permettent de faire une recherche croisée sur plusieurs mots clés en une seule opération de recherche, mais risquent d’aboutir à de «fausses chutes» si l’on n’a pas pris la précaution de codifier également les relations entre les mots clés et d’échancrer les trous correspondant aux relations. Car il faut pouvoir faire la distinction entre «l’action de A sur B» et «l’action de B sur A». Certaines fiches à trous centraux ont été conçues pour une sélection visuelle, mais le triage de la plupart des fiches à perforations centrales se fait mécaniquement. On glisse les fiches entre deux rouleaux métalliques reliés à un circuit électrique. Des brosses métalliques sont adaptées à l’un des rouleaux. Là où un trou a été percé, les rouleaux font contact, bouclant un circuit électrique qui active un mécanisme expulsant cette fiche du paquet. Ces machines peuvent aussi servir à imprimer un fichier complet sous forme de livre.L’automatisation a désormais permis, pour l’essentiel, de remplacer ces procédés par l’utilisation d’ordinateurs, dans lesquels les fichiers-index sont entrés par l’intermédiaire d’un clavier et stockés sur des bandes magnétiques ou des disques. La recherche se fait au moyen du même clavier, et les résultats de chaque opération de recherche s’affichent sur un écran vidéotexte. Les progrès de la technologie informatique ont bien évidemment influé sur l’indexation, tant au niveau des pratiques d’indexation et de recherche qu’au niveau des théories traitant des divers langages documentaires.Au début, quand l’ordinateur semblait offrir un potentiel de consultation et de recherche presque illimité grâce à la coordination de plusieurs termes ou mots clés distincts, beaucoup d’auteurs ont soutenu que les langages normalisés ou contrôlés n’étaient plus nécessaires pour les systèmes de codification et d’indexation: ils croyaient qu’une indexation «libre» par terme, à partir du langage naturel des auteurs, permettrait une consultation efficace. Sur ces bases ont été publiés certains index de types nouveaux. Le premier à connaître un succès appréciable s’appelait KWIC (key word in context : mot clé dans le contexte). Ce type d’index utilise les titres des documents tels qu’ils sont donnés par les auteurs, ce qui permet de se passer de spécialistes de l’indexation. Chacun des mots clés du titre est, tour à tour, placé au centre de la page, et chaque entrée ne comporte qu’une seule ligne dactylographiée; les autres mots sont déplacés à droite et à gauche le long de cette ligne, selon que chaque mot clé occupe telle ou telle position dans le titre; la liste est imprimée en suivant l’ordre alphabétique des mots au centre de la page.Une forme améliorée de l’index KWIC a reçu le nom de key word out of context (mot clé hors du contexte), soit KWOC. Il s’agissait de répondre à l’une des critiques adressées au KWIC, à savoir l’aspect peu agréable de l’impression de chaque mot clé à son tour en début de ligne, suivi normalement du titre du document sous sa forme habituelle.D’autres critiques sont plus importantes. D’abord le fait que le titre d’un texte ne décrit pas toujours le sujet de façon assez précise pour qu’on puisse retrouver commodément l’information. Ensuite que cette indexation «libre» des textes ne permet pas de rapprocher des sujets qui sont étroitement apparentés ou même désignés par des synonymes. Dans un des index KWIC américains, on trouve des titres qui ont pour mots clés À l’étranger , Étranger et Outre-mer , qui sont presque des synonymes, mais ces titres se trouvent dispersés un peu partout dans l’index parce que les initiales des mots clés sont différentes. On a bien essayé d’amener les auteurs à rédiger des titres plus pertinents, mais sans grand succès, et on s’est même heurté à de fortes résistances. Cependant, la technique KWIC peut être maniée de façon plus satisfaisante par des indexeurs professionnels utilisant un vocabulaire contrôlé pour choisir les mots clés, au lieu de s’en tenir aux mots figurant dans les titres.Le Bulletin signalétique du C.N.R.S. est publié en plusieurs parties et contient des résumés de publications récentes parues dans un grand nombre de pays. La section 101, «sciences de l’information», contient une suite de résumés répartis en sept classes de 01 à 07, avec un index alphabétique permuté en français et en anglais comportant à la fin de chaque entrée le numéro du résumé. Les éditions du Bulletin utilisaient initialement un format de type KWIC:
Il en existe encore d’autres, mais les éditeurs recommandent de ne pas en abuser. Comme ils ne se suivent pas selon un ordre connu ou naturel permettant leur classement, il a fallu expliciter cet aspect non séquentiel; dans un index de très grande dimension, comme celui dont a été dotée la bibliothèque du Science Museum de Londres, la complexité des numéros de classement désignant des sujets très spécialisés devient, pour les usagers, une gêne plutôt qu’une aide.Le principe qui consiste à combiner l’analyse et la synthèse afin de spécifier un sujet, au sein d’un système universel, donne à présent l’impulsion principale aux perfectionnements théoriques et pratiques de l’indexation matières. Plusieurs tables auxiliaires (Auxiliary Schedules) ont été fournies par H. E. Bliss dans un livre Bibliographic Classification , dont J. Mills et le British Classification Research Group (groupe britannique de recherches sur la classification) préparent en ce moment la deuxième édition.Celle-ci et les éditions récentes de la D.D.C. et de la C.D.U. ont toutes été fortement influencées par l’œuvre du bibliothécaire indien S. R. Ranganathan, qui traite de tous les aspects des bibliothèques. Sa théorie de l’«analyse par facettes» (Facet Analysis) rend possible un nouveau système général pour dresser des index par sujet. Son propre système, la C.C. (Colon Classification), n’est pas souvent utilisé, sauf en Inde, mais la théorie qui en est la base a été très largement acceptée et a servi à édifier des systèmes de classement pour beaucoup d’organismes spécialisés.3. L’analyse par facettesAvant la publication de la C.C., les systèmes de classification se fondaient sur le principe de l’analyse: il s’agissait d’énumérer des sujets, simples et complexes, en les disposant autant que possible selon des hiérarchies génériques ou pseudo-génériques, comme celle qui distingue le tout de la partie. Au contraire, dans la C.C., seules les hiérarchies génériques vraies sont énumérées; pour subdiviser davantage, on se sert de termes empruntés à diverses catégories, ou «facettes». Une théorie similaire a été élaborée indépendamment dans d’autres pays. L’idée fondamentale est que les concepts qui font partie d’un domaine de connaissance sont susceptibles d’être analysés et groupés ainsi en diverses catégories de termes clairement définis et distincts les uns des autres. Ranganathan a suggéré que ces catégories pourraient s’apparenter à cinq notions fondamentales: Temps, Espace, Matière, Énergie et ce qu’il appelle Personnalité. À l’intérieur de chaque sujet, il a appelé «facettes» les groupes de termes tirés de ces catégories fondamentales, et dans chaque sujet la notion centrale qui lui donne son identité spécifique constitue sa Personnalité. Un spécialiste doit s’attendre à voir groupés, sous cet aspect, les ouvrages qu’il a produits.Cette notion de Personnalité appliquée à un sujet se rapproche de l’idée centrale de la théorie générale des systèmes élaborée par Ludwig von Bertalanffy et d’autres, en particulier aux États-Unis. La théorie se présente comme une exploration scientifique des idées de Total et de Totalité, entités qui présentent une série de niveaux dont l’organisation est de plus en plus complexe. Elle se donne pour but de formuler des principes généraux pour tous les systèmes, quelles qu’en soient les entités élémentaires et quelles que soient les relations qui unissent celles-ci. Dans la C.C., ces entités sont définies par le terme de Personnalité, leurs relations par celui d’Énergie; les parties et les matériaux dont se compose une entité sont classés sous Matière, et une entité qui, à un certain niveau d’organisation, au sein d’une certaine classe, figure comme Personnalité, peut devenir Matière là où elle n’est qu’un des éléments contribuant à former une entité douée de Personnalité appartenant à un niveau supérieur.Ranganathan a été le premier à utiliser la méthode qui consiste à édifier des systèmes de classification multidimensionnels. La puissance de cette méthode et de celles qui s’y apparentent est bien montrée par le nombre de systèmes spécialisés qui les utilisent. Ils n’ont pas tous défini leurs «facettes» en fonction de cinq catégories fondamentales, telles qu’elles sont rapportées par l’Union française de documentation dans les années quarante et cinquante, et présentées dans l’étude faite par Éric de Groslier pour l’U.N.E.S.C.O. Cette puissance tient à l’intégration de deux facteurs: le modèle traditionnel de hiérarchie générique et le modèle moderne d’un système à mailles, ou réseau. Dans le premier, une espèce est définie par la présence d’une caractéristique générique qui la distingue des autres et conditionne son existence, mais, dans les classifications plus anciennes, telles que la C.D.U., l’application de ce modèle était élargie à toutes les subdivisions d’un sujet, simples ou complexes, sans égard à la relation qui existait en réalité entre le genre et l’espèce. Dans un réseau, les concepts sont énumérés un par un en des séquences distinctes; chaque groupe de concepts provient d’une division selon une et une seule caractéristique. Grâce à cette intégration, on obtient un ensemble de séquences, au lieu d’une seule séquence dans laquelle plusieurs caractéristiques se trouvent confondues, et on peut au gré des besoins ménager des intersections exprimant des relations spécifiques entre tout terme d’une séquence et tout terme d’une autre.Dans la C.C., au sein de la classe J, Agriculture, la facette P contient les noms des récoltes, la facette E les noms des procédés, et le symbole qui sert à combiner deux termes est le deux-points:– J 381 riz– J: 7 action de récolter (procédés de récolte)– J 381: 7 récolte du riz.Une classification introduite en pédologie (science des sols) par B. J. Vickery utilise la même méthode avec un autre jeu de symboles:– 9 (types de sol), 9 IQ (limon rouge)– 5 (actions sur les sols), 5 UB (érosion par le vent)– 9 IQ 5 UB (érosion des limons rouges par le vent).4. SYNTOLL’analyse par facettes fut l’aboutissement d’une longue histoire, celle des systèmes de classification et des index matières dans les bibliothèques; et il a été prouvé que l’analyse catégorielle s’adapte aisément aux systèmes automatisés tels que les enregistrements MARC. Le système appelé SYNTOL (Syntagmatic Organisation Language, langage systématique d’organisation) fut conçu par J.-C. Gardin et ses collègues du C.N.R.S. et de la Maison des sciences de l’homme, avec le soutien de l’Euratom, précisément en tant que modèle général d’un système d’indexation automatique. Il s’appuie sur les théories fondamentales de la structure des langues, notamment celle de F. de Saussure, et donc peut tout aussi bien s’appliquer aux systèmes non automatisés. J.-C. Gardin, en tant qu’archéologue, a été conduit à utiliser l’analyse catégorielle pour identifier les artefacts. Contrairement à la plupart des autres systèmes, il part d’une analyse des relations entre sujets et ne cherche pas à dresser des listes de termes telles qu’on en trouve dans les classifications conventionnelles, mais plutôt à établir un métalangage auquel on puisse relier d’autres systèmes. Il consiste en une ossature linguistique codifiée servant à représenter les données, et en un ensemble d’opérations logiques permettant de stocker les descriptions de documents et de les retrouver.SYNTOL a été l’un des premiers systèmes à expliciter la distinction entre deux modes d’organisation des termes signifiants, le mode sémantique et le mode syntaxique. À l’exemple de Saussure, il utilise les deux adjectifs «paradigmatique» et «syntagmatique» pour exprimer cette distinction. Les relations paradigmatiques sont a priori et existent dans le monde réel; celui des phénomènes, indépendamment de la présence d’aucun énoncé ou document. Elles sont reflétées par la structure des systèmes précoordonnés tels que les classifications ou les listes de vedettes matières. Les relations syntagmatiques sont a posteriori et s’appliquent à des énoncés spécifiques ou à des descriptions spécifiques de documents, comme les énoncés et les descriptions que fournit l’analyse par facettes de la C.C. ou d’autres systèmes similaires. Les tables de la C.C. comportent une seule relation entre genre et espèce, entre partie et tout, entre objet et processus; l’action de classer un document exprime les relations syntagmatiques entre les diverses facettes du sujet de ce document.Au début, SYNTOL ne fut appliqué qu’à un petit nombre de disciplines: la physiologie, la psychologie, la sociologie et l’anthropologie culturelle. Mais il est vrai, comme l’affirment ses auteurs, qu’un système d’analyse documentaire qui réussit dans des disciplines dont le langage est loin d’être standardisé se montrera probablement utile dans les domaines où la terminologie est plus précise. SYNTOL spécifie en outre deux groupes de facettes distincts: Source et Thématiques. Dans Source, les rubriques se réfèrent à des attributs physiques comme la forme, la langue et la date; la facette Thématiques inclut les Êtres (personnes ou groupes), le Thème (catégorie de phénomènes telle que la parenté ou la religion), le Temps (évoque des événements), l’Espace (lieu où se manifestent les personnes ou les événements) et le Mode (la manière générale d’aborder le sujet: historique, critique, etc.). Cette terminologie fait ressortir l’intention qui anime l’analyse, comme dans les catégories fondamentales de Ranganathan, et ce système a influencé une grande partie des recherches ultérieures, en particulier pour l’indexation des objets archéologiques.5. La codification et la notationAfin de pouvoir fixer l’ordre de succession des termes dans un classement ordonné, un système doit posséder un outil supplémentaire: un moyen de notation, c’est-à-dire un ensemble de symboles de codification dont la loi de succession soit déjà familière au public. Les deux ensembles les plus connus sont l’alphabet romain et les chiffres arabes; ils ont chacun un sens qui est toujours le même dans tous les pays. Ainsi, chaque élément d’un de ces ensembles assigne au sujet qui lui a été attribué un rang, une position fixe et déterminée au sein d’une succession. Un système multidimensionnel à facettes a besoin que sa notation possède deux caractéristiques principales: des indicateurs de facette et des indicateurs de terme. Ainsi, dans la C.C., les facettes sont signalées par des signes de ponctuation, dans la science des sols par des chiffres arabes, tandis que les termes sont signalés dans la C.C. par des numéros et dans la science des sols par des lettres. Ces deux systèmes sont indépendants des langues.Certaines expériences ont été menées, dans lesquelles on se servait des lettres de l’alphabet romain pour former des syllabes prononçables (G. Cordonnier, au centre de documentation d’Électricité de France, et D. J. Foskett, au London Education Classification – centre de classification pédagogique de l’agglomération de Londres). En dehors du projet Intercocta de l’U.N.E.S.C.O., ce système n’a guère rencontré d’écho, mais des recherches aux États-Unis suggèrent que de telles «syllabes non signifiantes» améliorent nettement la valeur mnémonique des systèmes d’encodage.6. L’indexation alphabétique matièresUne suite ordonnée de sujets repose sur une conception particulière de l’organisation des connaissances; c’est la manière la plus commode de dresser un index matières, mais il faut qu’il y ait une clef permettant aux usagers d’en comprendre la structure. Cette clef est l’index alphabétique, qui donne le symbole de codification correspondant à chaque terme, de même qu’un dictionnaire donne une définition pour chaque mot. L’alphabet ne constitue pas un système permettant d’organiser les concepts en une structure logique, il permet seulement de ranger les mots et les lettres selon un ordre de succession, une série. Les lettres de l’alphabet sont des signes et non des symboles; une liste alphabétique de mots se présentera dans un ordre différent si on traduit les mots dans une autre langue.Cependant, la disposition alphabétique des sujets au sein d’un index a connu un succès considérable, surtout aux États-Unis, parce qu’elle est la façon la plus commode d’accéder à une série de mots. Le nom qu’on décidera de donner à un sujet peut rencontrer une approbation plus ou moins générale, alors qu’il est plus difficile de s’accorder sur la position qu’on attribuera à un sujet au sein d’une structure logique ou intellectuelle, car l’édification d’une telle structure est un processus beaucoup plus complexe que la simple désignation d’un sujet par un nom. Tout processus de codification, telle qu’une suite ordonnée de sujets, n’aboutit à un résultat utilisable que si le code a une clé, de même que toute serrure exige une clé: la clé fait partie intégrante de l’ensemble fonctionnel, mais à elle seule (sans la serrure) elle ne saurait assurer la fermeture de la porte.En fait, la désignation des sujets exige d’être (dans une certaine mesure) normalisée pour être utilisable de façon assez générale, surtout si la collection ou le fichier des documents sont appelés à être utilisés par le public. Depuis le XIXe siècle, les grandes bibliothèques, certains érudits, certaines institutions publient des listes de vedettes matières, présentées en ordre alphabétique. On parle aussi de catalogues matières. Ces listes répondent à une demande constante, puisque deux des plus populaires, celle de la bibliothèque du Congrès et celle de M. E. Sears, ont atteint respectivement leur neuvième et onzième édition, et que les rubriques de la liste LC (Library of Congress, bibliothèque du Congrès) figurent dans les enregistrements MARC II. Il existe un grand nombre de listes de vedettes matières, souvent appelées maintenant «mots clés» ou «descripteurs»: l’une des plus connues est le MeSH (Medical Subject Headings, vedettes matières médicales) de la Bibliothèque nationale de médecine des États-Unis, car elle est souvent utilisée pour l’indexation dans des systèmes automatisés.Bien que la disposition de ces codes, également appelés «langages descripteurs» (descriptor languages ), se fonde essentiellement sur l’alphabet, ils sont également capables d’exprimer des relations entre les sujets (c’est-à-dire une forme camouflée de classement) au moyen de renvois d’un mot à un autre, parfois à plusieurs autres. Ces renvois sont de deux sortes: «Voir» et «Voir aussi». Un renvoi Voir signifie que le premier terme ne doit pas être utilisé pour l’indexation mais que les entrées dans le fichier figurent sous le second mot, auquel on renvoie. Un renvoi Voir aussi signifie que, outre les entrées faites sous le premier terme, il existe aussi des entrées pertinentes correspondant à des ouvrages sur des sujets connexes, figurant sous les mots auxquels on renvoie:– Histoire (ancienne). Voir aussi Archéologie; Bible; Civilisations (antiques)...in Liste des vedettes matières de Sears .– Personnel des Forces arméesX Personnel militaire– KéfirXU Lait7. L’indexation automatiqueAssez tôt dans l’histoire de l’automatisation, on s’est rendu compte qu’on pourrait se servir de machines pour indexer. Les premiers procédés, qui convenaient particulièrement à des index de petite dimension, utilisaient des fiches sur lesquelles on avait imprimé un quadrillage de perforation. Ces fiches à perforation centrale ou marginale se répartissent en deux types: les fiches par terme, où chaque fiche représente un mot clé, et les fiches par item, où chaque fiche représente un document numéroté. Sur les fiches par terme, on perfore les cases correspondant aux numéros des documents qui traitent du sujet évoqué par le terme. Sur les fiches par item, on perfore les cases correspondant aux divers sujets dont traite le document (item) fiché. Certaines fiches sont destinées à être perforées sur les bords, d’autres dans les cases d’un quadrillage couvrant toute la fiche. Il existe plusieurs façons d’utiliser les fiches pour une recherche; pour les fiches à perforations marginales, on repère le trou correspondant au numéro du sujet recherché, on y enfonce une aiguille qui embroche toutes les fiches, et on soulève le paquet: on voit alors tomber les fiches où ce trou a été découpé. Ces procédés permettent de faire une recherche croisée sur plusieurs mots clés en une seule opération de recherche, mais risquent d’aboutir à de «fausses chutes» si l’on n’a pas pris la précaution de codifier également les relations entre les mots clés et d’échancrer les trous correspondant aux relations. Car il faut pouvoir faire la distinction entre «l’action de A sur B» et «l’action de B sur A». Certaines fiches à trous centraux ont été conçues pour une sélection visuelle, mais le triage de la plupart des fiches à perforations centrales se fait mécaniquement. On glisse les fiches entre deux rouleaux métalliques reliés à un circuit électrique. Des brosses métalliques sont adaptées à l’un des rouleaux. Là où un trou a été percé, les rouleaux font contact, bouclant un circuit électrique qui active un mécanisme expulsant cette fiche du paquet. Ces machines peuvent aussi servir à imprimer un fichier complet sous forme de livre.L’automatisation a désormais permis, pour l’essentiel, de remplacer ces procédés par l’utilisation d’ordinateurs, dans lesquels les fichiers-index sont entrés par l’intermédiaire d’un clavier et stockés sur des bandes magnétiques ou des disques. La recherche se fait au moyen du même clavier, et les résultats de chaque opération de recherche s’affichent sur un écran vidéotexte. Les progrès de la technologie informatique ont bien évidemment influé sur l’indexation, tant au niveau des pratiques d’indexation et de recherche qu’au niveau des théories traitant des divers langages documentaires.Au début, quand l’ordinateur semblait offrir un potentiel de consultation et de recherche presque illimité grâce à la coordination de plusieurs termes ou mots clés distincts, beaucoup d’auteurs ont soutenu que les langages normalisés ou contrôlés n’étaient plus nécessaires pour les systèmes de codification et d’indexation: ils croyaient qu’une indexation «libre» par terme, à partir du langage naturel des auteurs, permettrait une consultation efficace. Sur ces bases ont été publiés certains index de types nouveaux. Le premier à connaître un succès appréciable s’appelait KWIC (key word in context : mot clé dans le contexte). Ce type d’index utilise les titres des documents tels qu’ils sont donnés par les auteurs, ce qui permet de se passer de spécialistes de l’indexation. Chacun des mots clés du titre est, tour à tour, placé au centre de la page, et chaque entrée ne comporte qu’une seule ligne dactylographiée; les autres mots sont déplacés à droite et à gauche le long de cette ligne, selon que chaque mot clé occupe telle ou telle position dans le titre; la liste est imprimée en suivant l’ordre alphabétique des mots au centre de la page.Une forme améliorée de l’index KWIC a reçu le nom de key word out of context (mot clé hors du contexte), soit KWOC. Il s’agissait de répondre à l’une des critiques adressées au KWIC, à savoir l’aspect peu agréable de l’impression de chaque mot clé à son tour en début de ligne, suivi normalement du titre du document sous sa forme habituelle.D’autres critiques sont plus importantes. D’abord le fait que le titre d’un texte ne décrit pas toujours le sujet de façon assez précise pour qu’on puisse retrouver commodément l’information. Ensuite que cette indexation «libre» des textes ne permet pas de rapprocher des sujets qui sont étroitement apparentés ou même désignés par des synonymes. Dans un des index KWIC américains, on trouve des titres qui ont pour mots clés À l’étranger , Étranger et Outre-mer , qui sont presque des synonymes, mais ces titres se trouvent dispersés un peu partout dans l’index parce que les initiales des mots clés sont différentes. On a bien essayé d’amener les auteurs à rédiger des titres plus pertinents, mais sans grand succès, et on s’est même heurté à de fortes résistances. Cependant, la technique KWIC peut être maniée de façon plus satisfaisante par des indexeurs professionnels utilisant un vocabulaire contrôlé pour choisir les mots clés, au lieu de s’en tenir aux mots figurant dans les titres.Le Bulletin signalétique du C.N.R.S. est publié en plusieurs parties et contient des résumés de publications récentes parues dans un grand nombre de pays. La section 101, «sciences de l’information», contient une suite de résumés répartis en sept classes de 01 à 07, avec un index alphabétique permuté en français et en anglais comportant à la fin de chaque entrée le numéro du résumé. Les éditions du Bulletin utilisaient initialement un format de type KWIC: Les éditions les plus récentes ont abandonné ce format pour le remplacer par un format de type KWOC, mais avec une analyse par sujet remplaçant le titre, les points montrant la position qu’occupe dans l’analyse par sujet le mot servant de vedette:– Indexation automatiqueThesaurus, ..., Livre, 262– LivreThesaurus, Indexation automatique, ..., 262– Thesaurus..., Indexation automatique, Livre, 262.Ce type d’index, qu’on appelle «permuté» ou «rotatif», peut aisément être utilisé avec des symboles de classification, ce qui a l’avantage de faire figurer chaque entrée à côté de celles qui traitent de sujets apparentés mais différents, comme dans l’index ci-dessus, qui renvoie aux documents classifiés selon la London Education Classification (classification pédagogique de l’agglomération de Londres). Cet index, contrairement à celui du Bulletin du C.N.R.S., suivrait le même ordre si on le traduisait dans une autre langue.
Les éditions les plus récentes ont abandonné ce format pour le remplacer par un format de type KWOC, mais avec une analyse par sujet remplaçant le titre, les points montrant la position qu’occupe dans l’analyse par sujet le mot servant de vedette:– Indexation automatiqueThesaurus, ..., Livre, 262– LivreThesaurus, Indexation automatique, ..., 262– Thesaurus..., Indexation automatique, Livre, 262.Ce type d’index, qu’on appelle «permuté» ou «rotatif», peut aisément être utilisé avec des symboles de classification, ce qui a l’avantage de faire figurer chaque entrée à côté de celles qui traitent de sujets apparentés mais différents, comme dans l’index ci-dessus, qui renvoie aux documents classifiés selon la London Education Classification (classification pédagogique de l’agglomération de Londres). Cet index, contrairement à celui du Bulletin du C.N.R.S., suivrait le même ordre si on le traduisait dans une autre langue.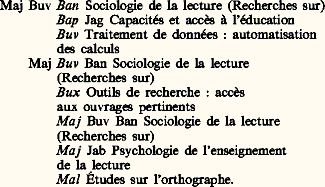 Les textes qui suivent les symboles de classification peuvent être des titres, comme ici, ou des mots clés comme dans l’actuel Bulletin du C.N.R.S.PRECISLes travaux du Groupe britannique de recherches sur la classification, qui ont abouti, dans ce domaine, à une autre édition de Bliss, BC 2, ont abouti également, dans le domaine de l’indexation alphabétique, au PRECIS (Preserved Context Indexing System, système d’indexation respectant le contexte). Celui-ci est connu parce qu’on s’en sert pour produire automatiquement les index alphabétiques matières de la British National Bibliography (Bibliographie nationale britannique). Les volumes plus anciens de celle-ci utilisaient l’«Indexation en chaîne», technique conçue par Ranganathan pour être utilisée avec une classification à facettes; avec la classification Dewey (D.D.C.), qui n’est pas à facettes, cette technique ne donnait pas entière satisfaction. Comme SYNTOL, PRECIS fait la distinction entre deux aspects de l’indexation, l’aspect «syntaxique» et celui qu’il appelle «thesaurus». Le premier consiste en relations syntagmatiques, et on l’applique quand il s’agit de spécifier les sujets que traite tel ou tel document. Le second s’identifie aux relations a priori telles qu’elles sont exprimées dans les listes de vedettes matières. Le fondement théorique de PRECIS provient de l’analyse par facettes, élaborée par la théorie générale des systèmes, et consiste en un ensemble de règles très détaillées qui prescrivent comment disposer une série de termes en une suite d’éléments appelés «chaînes». Ce mot «chaînes» a acquis une certaine popularité, particulièrement quand on l’applique à l’analyse documentaire liée à des programmes informatiques.Les index de citationsL’index de citations introduit un nouveau principe, celui de l’indexation par noms d’auteurs. Ces index sont publiés par l’Institute for Scientific Information (Institut pour l’information scientifique) de Philadelphie. Ils sont au nombre de trois: l’index de citations scientifiques (SCI), l’index de citations de sciences sociales (SSCI), l’index de citations artistiques et littéraires (AHCI). Leur but est d’enregistrer la façon dont progresse, historiquement, la contribution qu’un auteur apporte à son domaine. Ils reflètent cette progression en indexant les autres travaux qui se réfèrent aux travaux de l’auteur. La liste de citations qui concerne un auteur est présentée dans l’ordre chronologique de ses publications avec le nom de l’auteur comme vedette et les noms des auteurs qui le citent comme sous-vedettes. Les références indiquent les publications dans lesquelles il a été cité (cf. tableau).Les entrées BECHTOL et DORAN renvoient à des articles, signés de ces noms, qui citent deux travaux de J.-C. Gardin.Outre les index de citations par auteurs, l’Institut publie des index par sujets PERMUTERM, un index brevets, ainsi que certains volumes plus petits et plus spécialisés. Dans l’index PERMUTERM, une suite alphabétique de sous-vedettes figure sous chaque vedette principale, et les entrées sont placées sous la sous-vedette; aucune entrée ne figure donc sous le mot qui constitue la vedette principale, il y a seulement un renvoi «Voir» imprimé sous la forme sa (see also ). Les listes de mots vides sont des listes de mots que l’ordinateur ne doit pas utiliser comme vedettes:
Les textes qui suivent les symboles de classification peuvent être des titres, comme ici, ou des mots clés comme dans l’actuel Bulletin du C.N.R.S.PRECISLes travaux du Groupe britannique de recherches sur la classification, qui ont abouti, dans ce domaine, à une autre édition de Bliss, BC 2, ont abouti également, dans le domaine de l’indexation alphabétique, au PRECIS (Preserved Context Indexing System, système d’indexation respectant le contexte). Celui-ci est connu parce qu’on s’en sert pour produire automatiquement les index alphabétiques matières de la British National Bibliography (Bibliographie nationale britannique). Les volumes plus anciens de celle-ci utilisaient l’«Indexation en chaîne», technique conçue par Ranganathan pour être utilisée avec une classification à facettes; avec la classification Dewey (D.D.C.), qui n’est pas à facettes, cette technique ne donnait pas entière satisfaction. Comme SYNTOL, PRECIS fait la distinction entre deux aspects de l’indexation, l’aspect «syntaxique» et celui qu’il appelle «thesaurus». Le premier consiste en relations syntagmatiques, et on l’applique quand il s’agit de spécifier les sujets que traite tel ou tel document. Le second s’identifie aux relations a priori telles qu’elles sont exprimées dans les listes de vedettes matières. Le fondement théorique de PRECIS provient de l’analyse par facettes, élaborée par la théorie générale des systèmes, et consiste en un ensemble de règles très détaillées qui prescrivent comment disposer une série de termes en une suite d’éléments appelés «chaînes». Ce mot «chaînes» a acquis une certaine popularité, particulièrement quand on l’applique à l’analyse documentaire liée à des programmes informatiques.Les index de citationsL’index de citations introduit un nouveau principe, celui de l’indexation par noms d’auteurs. Ces index sont publiés par l’Institute for Scientific Information (Institut pour l’information scientifique) de Philadelphie. Ils sont au nombre de trois: l’index de citations scientifiques (SCI), l’index de citations de sciences sociales (SSCI), l’index de citations artistiques et littéraires (AHCI). Leur but est d’enregistrer la façon dont progresse, historiquement, la contribution qu’un auteur apporte à son domaine. Ils reflètent cette progression en indexant les autres travaux qui se réfèrent aux travaux de l’auteur. La liste de citations qui concerne un auteur est présentée dans l’ordre chronologique de ses publications avec le nom de l’auteur comme vedette et les noms des auteurs qui le citent comme sous-vedettes. Les références indiquent les publications dans lesquelles il a été cité (cf. tableau).Les entrées BECHTOL et DORAN renvoient à des articles, signés de ces noms, qui citent deux travaux de J.-C. Gardin.Outre les index de citations par auteurs, l’Institut publie des index par sujets PERMUTERM, un index brevets, ainsi que certains volumes plus petits et plus spécialisés. Dans l’index PERMUTERM, une suite alphabétique de sous-vedettes figure sous chaque vedette principale, et les entrées sont placées sous la sous-vedette; aucune entrée ne figure donc sous le mot qui constitue la vedette principale, il y a seulement un renvoi «Voir» imprimé sous la forme sa (see also ). Les listes de mots vides sont des listes de mots que l’ordinateur ne doit pas utiliser comme vedettes: En poursuivant une recherche à partir d’un nom d’auteur, en passant par les noms de ceux qui l’ont cité et en cherchant alors les citations répertoriées sous ces noms-là, on arrive à se faire une image claire de l’évolution historique d’un sujet dans son ensemble.ThesaurusDu fait que les imprimantes peuvent fournir les listes d’entrée concernant un document et les placer sous autant de vedettes qu’on le désire, les premiers utilisateurs furent tentés de rejeter tout vocabulaire contrôlé (tel qu’une liste de vedettes matières) et de s’en tenir aux termes du langage naturel choisis par les auteurs, comme dans les premiers index KWIC. Les défauts de cette méthode apparurent bientôt, et on introduisit le mot «thesaurus» pour désigner un vocabulaire contrôlé conçu en vue de l’utilisation avec des index automatisés. Comme SYNTOL, un thesaurus peut servir tout aussi bien pour un fichier établi à la main. L’usage du mot «thesaurus» pour désigner une liste de termes par sujets provient de l’ouvrage de P. M. Roget, Thesaurus of English Words and Phrases , publié en 1852, souvent réimprimé et révisé par la suite. Il comporte deux parties: la première est une liste de termes classés en catégories liées à des notions abstraites (Existence, Quantité, Matière, Temps, Espace, Facultés intellectuelles et morales, par exemple). Certaines recouvrent exactement les catégories fondamentales de Ranganathan, et chaque catégorie est subdivisée en notions plus concrètes, comme dans le système à facettes. La seconde partie est un index alphabétique qui renvoie à la liste des catégories classifiées.L’usage moderne du mot «thesaurus» en indexation fut introduit par H. P. Luhn d’I.B.M.; il parla également de «familles de notions», c’est-à-dire de catégories de termes, qui devaient servir de base à un thesaurus; celui-ci, muni d’une clé alphabétique, serait utilisé pour l’indexation automatique. Un grand nombre de spécialistes s’engouffrèrent dans cette brèche et se mirent à construire des thesaurus dans ce but. Les premiers provenaient des États-Unis et, à la différence du Roget, consistaient presque entièrement en une liste alphabétique; ils ne contenaient guère, en fait de systèmes de classification par catégories, que des ébauches assez grossières. Le système mondial d’information scientifique de l’U.N.E.S.C.O. (UNISIST) a publié une définition généralement acceptée de ce qu’est un thesaurus, fondée sur sa fonction et sa structure. Comme tout vocabulaire contrôlé, un thesaurus a plusieurs fonctions, mais les plus importantes sont: fournir un vocabulaire normalisé pour un domaine, de façon à assurer la cohérence du choix des termes d’indexation; fournir une structure de renvois telle que les relations entre les termes soient claires à la fois pour les indexeurs et pour ceux qui consultent l’index. Une classification bien conçue doit permettre l’insertion de termes nouveaux dans le thesaurus. Elle doit aussi se prêter à une modulation de la recherche informatisée, qui se fera plus générale ou plus spécifique, plus large ou plus étroite, si le terme qu’on a choisi en premier comme axe de recherche amène à faire sortir du fichier un nombre trop petit ou trop grand de références à des documents indexés dans le fichier. Beaucoup d’organismes nationaux et internationaux ont publié des thesaurus, ainsi que des instructions permettant de les construire ou de les utiliser.Au sein d’un thesaurus, la délimitation d’une catégorie de sujets est déterminée par le consensus des spécialistes de ce sujet, mais, lorsque le concepteur se conforme aux principes de l’analyse par facettes, la structure de la section reflétera fidèlement la logique interne du domaine considéré, puisque les noms des facettes sont empruntés aux termes tels qu’ils sont employés dans les documents et ouvrages eux-mêmes. On peut citer par exemple le Thesaurofacettes de l’ingénierie dans la English Electric Company, conçu par Jean Aitchison, qui fut par la suite l’auteur du thesaurus de l’U.N.E.S.C.O. Actuellement, les thesaurus contiennent une section systématique (outre leur section alphabétique) et parfois plusieurs. Le thesaurus des termes de science et d’ingénierie (TEST) du conseil supérieur des ingénieurs américains contient un «index permuté», un «index matières par catégorie», et un «index hiérarchique».Outre les listes de termes – les «descripteurs» –, un thesaurus contient deux autres éléments importants: des définitions expliquant ce que signifient les termes et des symboles exprimant les relations qui les unissent. Ces deux éléments se trouvent d’habitude dans la section alphabétique et leur introduction a été plus ou moins normalisée sous la forme suivante:– SN (Scope Note): «Note d’application», indication d’extension, définit ou explique un terme.– USE: équivalent à un renvoi Voir pour un terme non utilisé.– UF (Use for): la réciproque de USE, placée sous le terme qui est effectivement employé.– BT (Broader Term): terme générique dans une disposition hiérarchique, se réfère à la rubrique plus générale placée immédiatement au-dessus.– NT (Narrower Term): terme spécifique, renvoie au descripteur plus spécifique placé immédiatement au-dessous.– RT (Related Term): terme associé, renvoie à un ou plusieurs termes qui ont avec le premier un rapport utilisable, mais ne figurent pas dans la même hiérarchie.Il existe diverses variantes et divers perfectionnements de ces symboles, mais ceux-ci sont les principaux et les plus utilisés.8. La recherche dans un indexUn bon index présente une structure intellectuelle complexe, et une certaine maîtrise est essentielle pour toute recherche, si simple qu’elle ait d’abord paru. Il faut concevoir une «stratégie de recherche» qui conduise le plus efficacement, donc le plus économiquement, jusqu’à l’information requise. Quand on consulte un fichier informatisé, cet itinéraire est celui qui correspond au temps de connexion le plus court.Même les index par auteurs posent des problèmes. Un auteur peut avoir pris des pseudonymes, avoir écrit sous plusieurs noms, avoir publié en collaboration comme coauteur. Les institutions produisent des documents dont elles sont auteur collectif, sans nom de personne. Certains documents ne portent pas de nom d’auteur et sont catalogués comme «anonymes». Toute stratégie de consultation exige donc qu’on connaisse d’abord bien les principes selon lesquels l’index a été conçu, c’est-à-dire le système des entrées et des renvois. Cela implique qu’on sache de quelle manière l’entrée figurant dans l’index désigne le document indexé et, bien qu’il existe un grand nombre de normes régissant ce genre de détails, aucun, pour l’instant, n’est universellement admis.Celui qui consulte un index matières a tout particulièrement besoin d’une stratégie de recherche. Dans une première étape, il procédera à une analyse précise afin d’identifier le sujet de sa recherche, par exemple en utilisant un ensemble de termes empruntés à des catégories qui s’excluent les unes les autres, comme c’est le cas dans l’analyse par facettes: objets, parties, propriétés, processus, etc. Lorsque les termes d’un index sont choisis dans une liste ou un thesaurus, il faut consulter cette source afin de savoir quels termes l’index utilise pour désigner le sujet recherché. La plupart des chercheurs commencent par énoncer leur sujet de façon très générale, bien que ce ne soit pas la meilleure manière de procéder. Dans des index imprimés comme l’étaient ceux du C.N.R.S., on peut, en cherchant un terme trop général, passer à côté de documents qui sont indexés par des descripteurs plus spécifiques. Dans un index informatisé (PASCAL et MYRIADE pour le C.N.R.S.), si on utilise un terme trop large, on se voit livrer un nombre de références tel qu’on ne pourra pas les exploiter en temps réel, si ce n’est à un coût prohibitif. Il faut donc ajouter des termes au descripteur choisi pour le rendre plus spécifique. Cela sera facilité par une analyse initiale détaillée du sujet. La plupart des fichiers informatisés se prêtent à des recherches qui s’inspirent de la logique de Boole à laquelle elles empruntent les relations AND, OR et NOT (ET, OU et SAUF).– Terme A OU terme B: affiche sur l’écran les références qui contiennent soit l’un, soit l’autre terme; il s’agit là de l’étape la plus générale de la recherche.– Terme A SAUF terme B: affiche les références qui contiennent le premier terme, mais pas le second; on a là quelque chose de plus spécifique mais qui inclura encore les termes C, D, E, etc.– Terme A ET terme B: affiche les références qui contiennent les deux termes à la fois; étape plus spécifique elle aussi, qui peut produire des références moins nombreuses que ne fait la relation SAUF.– Terme A ET terme B SAUF C SAUF D...: affiche les références qui contiennent A et B, à l’exclusion des autres termes; c’est la recherche la plus spécifique, mais ce n’est pas toujours la plus féconde.La recherche ayant été élargie ou rétrécie au point de fournir un nombre raisonnable de références ou «coups au but», l’étape suivante consiste à consulter les références elles-mêmes, ou des résumés s’il y en a. L’ordinateur peut afficher sur l’écran les trois ou quatre premières références, ce qui suffira à remplir l’écran et à montrer si la question posée a été formulée comme il convient. Le chercheur pourra alors demander une copie imprimée de l’ensemble des références fournies et aller dans une bibliothèque consulter les documents. Si la formulation se révèle incorrecte, il faut recommencer la recherche, ce qui démontre à quel point il est précieux de maîtriser convenablement cette technique.9. Indexation et intelligence artificielleL’indexation est une pratique ancienne indispensable pour retrouver rapidement les documents voulus. Jusqu’à une époque récente, elle semblait réservée à l’intelligence humaine. Car indexer ne consiste pas à créer des index (tâche facilement automatisable) mais à affecter aux documents des indices, des marques significatives de leur contenu, à la suite d’une série d’opérations mentales complexes et encore mal connues.Pourtant, l’indexation est atteinte à son tour par l’irrésistible progression des «machines à penser».Genèse des recherches en indexation automatiquePlusieurs facteurs ont incité les chercheurs en informatique documentaire à tenter de concurrencer l’indexation humaine. D’abord, les contraintes et les insuffisances inhérentes à celle-ci: elle est coûteuse (il faut entre un quart d’heure et une heure pour indexer un document); elle est tributaire de la subjectivité de l’indexeur (deux analystes différents indexent rarement un document de manière rigoureusement identique).À l’inverse, les coûts de traitement informatique ne cessent de baisser, et la machine est exempte de subjectivité.Un autre avantage de l’indexation automatique est de pouvoir analyser par le même procédé les textes des auteurs et les requêtes de l’utilisateur, alors que dans un système traditionnel celui-ci doit s’adapter aux termes choisis par l’indexeur.Encore faut-il que l’ordinateur puisse produire des formules d’indexation acceptables – sinon comparables à celles de l’indexeur. Or les dernières recherches en traitement informatique des langues (traduction automatique) et en sémantique (analyse conceptuelle, réseaux sémantiques, analyseur automatique de texte) ont mis à la disposition des concepteurs des outils efficaces, du moins pour les documents textuels, qui sont encore les plus nombreux.Fonction documentaire du texte et mots videsOn a observé depuis longtemps un trait remarquable des documents textuels: non seulement ils nous livrent des informations, mais ils nous renseignent aussi sur le sujet traité puisqu’il est impossible de parler d’un sujet sans le nommer. Autrement dit, un texte quelconque comporte, en plus de sa fonction principale d’information, une fonction accessoire d’auto-indexation.Comme, en outre, un ordinateur peut facilement isoler et reconnaître les mots d’un texte, le problème revient à sélectionner les mots les plus significatifs. Cela, certes, n’est pas une mince affaire. Mais une autre caractéristique remarquable, commune à toutes les langues, permet une première sélection à peu de frais: l’élimination des mots vides.Une phrase est composée approximativement pour moitié de termes lexicaux (les mots du dictionnaire), qui ont un sens en eux-mêmes, indépendamment du contexte, et de termes grammaticaux (prépositions, conjonctions, pronoms, adjectifs numéraux, etc.), qui n’ont pas de signification en dehors de leur contexte. La seconde catégorie étant en nombre limité (quelques centaines), il est facile d’en dresser la liste et de les faire éliminer automatiquement. Par exemple, dans la phrase «agiter la bouteille avant de s’en servir», un programme de sélection des mots significatifs retiendra «agiter», «bouteille», «servir». Un texte contenant cette phrase pourra donc être repéré à l’interrogation par l’un de ces termes ou par une combinaison de ceux-ci.La recherche en texte intégralCet exemple montre à la fois l’ingéniosité du procédé et la médiocrité du résultat. Les défauts de cette sélection rudimentaire sont évidents:– tous les mots non vides sont retenus sur le même plan, qu’ils soient ou non représentatifs du sujet principal du document ;– un mot variable, par exemple un verbe, apparaît souvent dans le même texte sous des flexions différentes (voir, vu, etc.), qui masquent leur appartenance au même mot type;– seuls sont prélevés des mots isolés (unitermes), alors que les termes significatifs sont souvent des «syntagmes» (pluritermes): chemin de fer, banque de données, sécurité sociale, etc.;– rappelons enfin les difficultés inhérentes à la recherche en langage naturel (synonymie, polysémie).Pourtant, malgré ses insuffisances, ce procédé rudimentaire a été utilisé dès les années 1960 et il s’est révélé efficace dans des applications particulières: les titres, qui sont des sortes de codes documentaires naturels, produisent les index KWIC ou KWOC, déjà mentionnés; les logiciels de recherche en texte intégral (ou: texte libre) donnent de bons résultats quand ils s’appliquent à des textes courts et à des domaines spécifiques.Par exemple, les dépêches de l’Agence France-Presse, indexées quotidiennement sans aucune intervention humaine, peuvent être facilement retrouvées grâce au caractère très sélectif des noms propres et des dates qui repèrent un événement (base de données AGORA).Par ailleurs, la plupart des bases de données scientifiques (PASCAL) ou journalistiques (La Croix ) offrent, en complément de l’interrogation sur les termes contrôlés choisis par les indexeurs, la possibilité d’interroger en vocabulaire libre sur les mots prélevés automatiquement dans les titres (et parfois les résumés).Les performances peuvent être améliorées si l’on utilise la troncature (interrogation sur la racine d’un mot, comme ‘ aliment ’ pour ‘ alimenter, alimentation, alimentaire ’). De plus, les opérateurs de proximité permettent de spécifier les conditions de distance entre les termes choisis. Par exemple, la question «base (+1) données» sélectionnera «base de données» mais éliminera «données de base» ou «bases de l’accord données pour acquises».L’indexation sélective «intelligente»Plusieurs équipes de chercheurs pensent qu’on peut aller beaucoup plus loin dans la qualité de l’indexation automatique en utilisant ingénieusement certaines propriétés du langage et des produits du langage (le discours). Ici, l’indexation du document n’est plus traitée de façon autonome, mais conçue comme élément du système d’information dont le pendant est l’indexation de la question.La fréquence d’utilisation des termes dans le discours fournit des indications utiles. Pour tenir le rôle d’un bon descripteur, un terme doit différencier fortement le document auquel il est attaché des autres documents. Or, en relevant dans un grand nombre de textes le nombre d’apparitions (occurrences) de tous les mots, on peut affecter à chacun un indice moyen de fréquence (par exemple: 1/1 000). Si, dans un document textuel, l’indice de fréquence d’un mot non vide est très supérieur à son indice moyen, il y a de fortes raisons de penser qu’il s’agit d’un bon descripteur. On peut facilement calculer pour chaque mot du texte à indexer le rapport entre les deux indices et imposer un seuil (par exemple: face=F0019 礪 3) à ce rapport afin d’éliminer les termes les moins significatifs.L’analyse morpho-syntaxique des textes , aujourd’hui largement maîtrisée, offre de nombreuses ressources: on a remarqué que les noms (et particulièrement les noms sujets) étaient plus représentatifs du thème d’un document que les verbes ou les adjectifs. En reconnaissant la catégorie grammaticale et la fonction d’un mot, un programme informatique permet de pondérer les mots non vides selon ces critères. De plus, l’identification des terminaisons des mots variables, couplée à la consultation d’un dictionnaire de la langue, permet de reconnaître sous la diversité des formes l’appartenance à un même mot type.D’autres chercheurs s’attaquent à la faiblesse principale de l’indexation automatique: la sélection de mots isolés. La reconnaissance des syntagmes nominaux (moteur d’alternateur, indexation automatique) et de leur fonction syntaxique permet une recherche beaucoup plus précise. L’équipe lyonnaise SYDO (G. Bouché et M. Le Guern) travaille à affiner cette méthode prometteuse.En intégrant un réseau de relations sémantiques aux systèmes d’analyse automatique du contenu, on peut aller encore plus loin, et fournir à l’ordinateur un semblant de connaissance des concepts et de leurs relations. Ces méthodes relèvent des systèmes experts, très en vogue depuis quelques années. Si, par exemple, on intègre à un logiciel un thesaurus (cf. L’indexation automatique ), on peut enrichir l’indexation en ajoutant aux termes retenus des termes équivalents ou plus généraux (exemple: vérificationcontrôle, surveillance).Ces systèmes, dont plusieurs ont fait leur preuve, restent coûteux en temps machine. Il est probable qu’ils ne rivaliseront jamais avec la finesse de l’indexation humaine. Mais ils peuvent en être un complément ou même un substitut. Les années 1990 ont permis le développement de tels systèmes, parallèlement à la traduction assistée par ordinateur.Signalons le foisonnement des logiciels commercialisés, SPIRIT (méthode statistique et linguistique), ALEXIS (méthode linguistique et sémantique), SINTEX (sélection automatique de descripteurs soumise au contrôle d’un indexeur), BASIS, TEXTO, SUPERDOC et leurs diverses versions.
En poursuivant une recherche à partir d’un nom d’auteur, en passant par les noms de ceux qui l’ont cité et en cherchant alors les citations répertoriées sous ces noms-là, on arrive à se faire une image claire de l’évolution historique d’un sujet dans son ensemble.ThesaurusDu fait que les imprimantes peuvent fournir les listes d’entrée concernant un document et les placer sous autant de vedettes qu’on le désire, les premiers utilisateurs furent tentés de rejeter tout vocabulaire contrôlé (tel qu’une liste de vedettes matières) et de s’en tenir aux termes du langage naturel choisis par les auteurs, comme dans les premiers index KWIC. Les défauts de cette méthode apparurent bientôt, et on introduisit le mot «thesaurus» pour désigner un vocabulaire contrôlé conçu en vue de l’utilisation avec des index automatisés. Comme SYNTOL, un thesaurus peut servir tout aussi bien pour un fichier établi à la main. L’usage du mot «thesaurus» pour désigner une liste de termes par sujets provient de l’ouvrage de P. M. Roget, Thesaurus of English Words and Phrases , publié en 1852, souvent réimprimé et révisé par la suite. Il comporte deux parties: la première est une liste de termes classés en catégories liées à des notions abstraites (Existence, Quantité, Matière, Temps, Espace, Facultés intellectuelles et morales, par exemple). Certaines recouvrent exactement les catégories fondamentales de Ranganathan, et chaque catégorie est subdivisée en notions plus concrètes, comme dans le système à facettes. La seconde partie est un index alphabétique qui renvoie à la liste des catégories classifiées.L’usage moderne du mot «thesaurus» en indexation fut introduit par H. P. Luhn d’I.B.M.; il parla également de «familles de notions», c’est-à-dire de catégories de termes, qui devaient servir de base à un thesaurus; celui-ci, muni d’une clé alphabétique, serait utilisé pour l’indexation automatique. Un grand nombre de spécialistes s’engouffrèrent dans cette brèche et se mirent à construire des thesaurus dans ce but. Les premiers provenaient des États-Unis et, à la différence du Roget, consistaient presque entièrement en une liste alphabétique; ils ne contenaient guère, en fait de systèmes de classification par catégories, que des ébauches assez grossières. Le système mondial d’information scientifique de l’U.N.E.S.C.O. (UNISIST) a publié une définition généralement acceptée de ce qu’est un thesaurus, fondée sur sa fonction et sa structure. Comme tout vocabulaire contrôlé, un thesaurus a plusieurs fonctions, mais les plus importantes sont: fournir un vocabulaire normalisé pour un domaine, de façon à assurer la cohérence du choix des termes d’indexation; fournir une structure de renvois telle que les relations entre les termes soient claires à la fois pour les indexeurs et pour ceux qui consultent l’index. Une classification bien conçue doit permettre l’insertion de termes nouveaux dans le thesaurus. Elle doit aussi se prêter à une modulation de la recherche informatisée, qui se fera plus générale ou plus spécifique, plus large ou plus étroite, si le terme qu’on a choisi en premier comme axe de recherche amène à faire sortir du fichier un nombre trop petit ou trop grand de références à des documents indexés dans le fichier. Beaucoup d’organismes nationaux et internationaux ont publié des thesaurus, ainsi que des instructions permettant de les construire ou de les utiliser.Au sein d’un thesaurus, la délimitation d’une catégorie de sujets est déterminée par le consensus des spécialistes de ce sujet, mais, lorsque le concepteur se conforme aux principes de l’analyse par facettes, la structure de la section reflétera fidèlement la logique interne du domaine considéré, puisque les noms des facettes sont empruntés aux termes tels qu’ils sont employés dans les documents et ouvrages eux-mêmes. On peut citer par exemple le Thesaurofacettes de l’ingénierie dans la English Electric Company, conçu par Jean Aitchison, qui fut par la suite l’auteur du thesaurus de l’U.N.E.S.C.O. Actuellement, les thesaurus contiennent une section systématique (outre leur section alphabétique) et parfois plusieurs. Le thesaurus des termes de science et d’ingénierie (TEST) du conseil supérieur des ingénieurs américains contient un «index permuté», un «index matières par catégorie», et un «index hiérarchique».Outre les listes de termes – les «descripteurs» –, un thesaurus contient deux autres éléments importants: des définitions expliquant ce que signifient les termes et des symboles exprimant les relations qui les unissent. Ces deux éléments se trouvent d’habitude dans la section alphabétique et leur introduction a été plus ou moins normalisée sous la forme suivante:– SN (Scope Note): «Note d’application», indication d’extension, définit ou explique un terme.– USE: équivalent à un renvoi Voir pour un terme non utilisé.– UF (Use for): la réciproque de USE, placée sous le terme qui est effectivement employé.– BT (Broader Term): terme générique dans une disposition hiérarchique, se réfère à la rubrique plus générale placée immédiatement au-dessus.– NT (Narrower Term): terme spécifique, renvoie au descripteur plus spécifique placé immédiatement au-dessous.– RT (Related Term): terme associé, renvoie à un ou plusieurs termes qui ont avec le premier un rapport utilisable, mais ne figurent pas dans la même hiérarchie.Il existe diverses variantes et divers perfectionnements de ces symboles, mais ceux-ci sont les principaux et les plus utilisés.8. La recherche dans un indexUn bon index présente une structure intellectuelle complexe, et une certaine maîtrise est essentielle pour toute recherche, si simple qu’elle ait d’abord paru. Il faut concevoir une «stratégie de recherche» qui conduise le plus efficacement, donc le plus économiquement, jusqu’à l’information requise. Quand on consulte un fichier informatisé, cet itinéraire est celui qui correspond au temps de connexion le plus court.Même les index par auteurs posent des problèmes. Un auteur peut avoir pris des pseudonymes, avoir écrit sous plusieurs noms, avoir publié en collaboration comme coauteur. Les institutions produisent des documents dont elles sont auteur collectif, sans nom de personne. Certains documents ne portent pas de nom d’auteur et sont catalogués comme «anonymes». Toute stratégie de consultation exige donc qu’on connaisse d’abord bien les principes selon lesquels l’index a été conçu, c’est-à-dire le système des entrées et des renvois. Cela implique qu’on sache de quelle manière l’entrée figurant dans l’index désigne le document indexé et, bien qu’il existe un grand nombre de normes régissant ce genre de détails, aucun, pour l’instant, n’est universellement admis.Celui qui consulte un index matières a tout particulièrement besoin d’une stratégie de recherche. Dans une première étape, il procédera à une analyse précise afin d’identifier le sujet de sa recherche, par exemple en utilisant un ensemble de termes empruntés à des catégories qui s’excluent les unes les autres, comme c’est le cas dans l’analyse par facettes: objets, parties, propriétés, processus, etc. Lorsque les termes d’un index sont choisis dans une liste ou un thesaurus, il faut consulter cette source afin de savoir quels termes l’index utilise pour désigner le sujet recherché. La plupart des chercheurs commencent par énoncer leur sujet de façon très générale, bien que ce ne soit pas la meilleure manière de procéder. Dans des index imprimés comme l’étaient ceux du C.N.R.S., on peut, en cherchant un terme trop général, passer à côté de documents qui sont indexés par des descripteurs plus spécifiques. Dans un index informatisé (PASCAL et MYRIADE pour le C.N.R.S.), si on utilise un terme trop large, on se voit livrer un nombre de références tel qu’on ne pourra pas les exploiter en temps réel, si ce n’est à un coût prohibitif. Il faut donc ajouter des termes au descripteur choisi pour le rendre plus spécifique. Cela sera facilité par une analyse initiale détaillée du sujet. La plupart des fichiers informatisés se prêtent à des recherches qui s’inspirent de la logique de Boole à laquelle elles empruntent les relations AND, OR et NOT (ET, OU et SAUF).– Terme A OU terme B: affiche sur l’écran les références qui contiennent soit l’un, soit l’autre terme; il s’agit là de l’étape la plus générale de la recherche.– Terme A SAUF terme B: affiche les références qui contiennent le premier terme, mais pas le second; on a là quelque chose de plus spécifique mais qui inclura encore les termes C, D, E, etc.– Terme A ET terme B: affiche les références qui contiennent les deux termes à la fois; étape plus spécifique elle aussi, qui peut produire des références moins nombreuses que ne fait la relation SAUF.– Terme A ET terme B SAUF C SAUF D...: affiche les références qui contiennent A et B, à l’exclusion des autres termes; c’est la recherche la plus spécifique, mais ce n’est pas toujours la plus féconde.La recherche ayant été élargie ou rétrécie au point de fournir un nombre raisonnable de références ou «coups au but», l’étape suivante consiste à consulter les références elles-mêmes, ou des résumés s’il y en a. L’ordinateur peut afficher sur l’écran les trois ou quatre premières références, ce qui suffira à remplir l’écran et à montrer si la question posée a été formulée comme il convient. Le chercheur pourra alors demander une copie imprimée de l’ensemble des références fournies et aller dans une bibliothèque consulter les documents. Si la formulation se révèle incorrecte, il faut recommencer la recherche, ce qui démontre à quel point il est précieux de maîtriser convenablement cette technique.9. Indexation et intelligence artificielleL’indexation est une pratique ancienne indispensable pour retrouver rapidement les documents voulus. Jusqu’à une époque récente, elle semblait réservée à l’intelligence humaine. Car indexer ne consiste pas à créer des index (tâche facilement automatisable) mais à affecter aux documents des indices, des marques significatives de leur contenu, à la suite d’une série d’opérations mentales complexes et encore mal connues.Pourtant, l’indexation est atteinte à son tour par l’irrésistible progression des «machines à penser».Genèse des recherches en indexation automatiquePlusieurs facteurs ont incité les chercheurs en informatique documentaire à tenter de concurrencer l’indexation humaine. D’abord, les contraintes et les insuffisances inhérentes à celle-ci: elle est coûteuse (il faut entre un quart d’heure et une heure pour indexer un document); elle est tributaire de la subjectivité de l’indexeur (deux analystes différents indexent rarement un document de manière rigoureusement identique).À l’inverse, les coûts de traitement informatique ne cessent de baisser, et la machine est exempte de subjectivité.Un autre avantage de l’indexation automatique est de pouvoir analyser par le même procédé les textes des auteurs et les requêtes de l’utilisateur, alors que dans un système traditionnel celui-ci doit s’adapter aux termes choisis par l’indexeur.Encore faut-il que l’ordinateur puisse produire des formules d’indexation acceptables – sinon comparables à celles de l’indexeur. Or les dernières recherches en traitement informatique des langues (traduction automatique) et en sémantique (analyse conceptuelle, réseaux sémantiques, analyseur automatique de texte) ont mis à la disposition des concepteurs des outils efficaces, du moins pour les documents textuels, qui sont encore les plus nombreux.Fonction documentaire du texte et mots videsOn a observé depuis longtemps un trait remarquable des documents textuels: non seulement ils nous livrent des informations, mais ils nous renseignent aussi sur le sujet traité puisqu’il est impossible de parler d’un sujet sans le nommer. Autrement dit, un texte quelconque comporte, en plus de sa fonction principale d’information, une fonction accessoire d’auto-indexation.Comme, en outre, un ordinateur peut facilement isoler et reconnaître les mots d’un texte, le problème revient à sélectionner les mots les plus significatifs. Cela, certes, n’est pas une mince affaire. Mais une autre caractéristique remarquable, commune à toutes les langues, permet une première sélection à peu de frais: l’élimination des mots vides.Une phrase est composée approximativement pour moitié de termes lexicaux (les mots du dictionnaire), qui ont un sens en eux-mêmes, indépendamment du contexte, et de termes grammaticaux (prépositions, conjonctions, pronoms, adjectifs numéraux, etc.), qui n’ont pas de signification en dehors de leur contexte. La seconde catégorie étant en nombre limité (quelques centaines), il est facile d’en dresser la liste et de les faire éliminer automatiquement. Par exemple, dans la phrase «agiter la bouteille avant de s’en servir», un programme de sélection des mots significatifs retiendra «agiter», «bouteille», «servir». Un texte contenant cette phrase pourra donc être repéré à l’interrogation par l’un de ces termes ou par une combinaison de ceux-ci.La recherche en texte intégralCet exemple montre à la fois l’ingéniosité du procédé et la médiocrité du résultat. Les défauts de cette sélection rudimentaire sont évidents:– tous les mots non vides sont retenus sur le même plan, qu’ils soient ou non représentatifs du sujet principal du document ;– un mot variable, par exemple un verbe, apparaît souvent dans le même texte sous des flexions différentes (voir, vu, etc.), qui masquent leur appartenance au même mot type;– seuls sont prélevés des mots isolés (unitermes), alors que les termes significatifs sont souvent des «syntagmes» (pluritermes): chemin de fer, banque de données, sécurité sociale, etc.;– rappelons enfin les difficultés inhérentes à la recherche en langage naturel (synonymie, polysémie).Pourtant, malgré ses insuffisances, ce procédé rudimentaire a été utilisé dès les années 1960 et il s’est révélé efficace dans des applications particulières: les titres, qui sont des sortes de codes documentaires naturels, produisent les index KWIC ou KWOC, déjà mentionnés; les logiciels de recherche en texte intégral (ou: texte libre) donnent de bons résultats quand ils s’appliquent à des textes courts et à des domaines spécifiques.Par exemple, les dépêches de l’Agence France-Presse, indexées quotidiennement sans aucune intervention humaine, peuvent être facilement retrouvées grâce au caractère très sélectif des noms propres et des dates qui repèrent un événement (base de données AGORA).Par ailleurs, la plupart des bases de données scientifiques (PASCAL) ou journalistiques (La Croix ) offrent, en complément de l’interrogation sur les termes contrôlés choisis par les indexeurs, la possibilité d’interroger en vocabulaire libre sur les mots prélevés automatiquement dans les titres (et parfois les résumés).Les performances peuvent être améliorées si l’on utilise la troncature (interrogation sur la racine d’un mot, comme ‘ aliment ’ pour ‘ alimenter, alimentation, alimentaire ’). De plus, les opérateurs de proximité permettent de spécifier les conditions de distance entre les termes choisis. Par exemple, la question «base (+1) données» sélectionnera «base de données» mais éliminera «données de base» ou «bases de l’accord données pour acquises».L’indexation sélective «intelligente»Plusieurs équipes de chercheurs pensent qu’on peut aller beaucoup plus loin dans la qualité de l’indexation automatique en utilisant ingénieusement certaines propriétés du langage et des produits du langage (le discours). Ici, l’indexation du document n’est plus traitée de façon autonome, mais conçue comme élément du système d’information dont le pendant est l’indexation de la question.La fréquence d’utilisation des termes dans le discours fournit des indications utiles. Pour tenir le rôle d’un bon descripteur, un terme doit différencier fortement le document auquel il est attaché des autres documents. Or, en relevant dans un grand nombre de textes le nombre d’apparitions (occurrences) de tous les mots, on peut affecter à chacun un indice moyen de fréquence (par exemple: 1/1 000). Si, dans un document textuel, l’indice de fréquence d’un mot non vide est très supérieur à son indice moyen, il y a de fortes raisons de penser qu’il s’agit d’un bon descripteur. On peut facilement calculer pour chaque mot du texte à indexer le rapport entre les deux indices et imposer un seuil (par exemple: face=F0019 礪 3) à ce rapport afin d’éliminer les termes les moins significatifs.L’analyse morpho-syntaxique des textes , aujourd’hui largement maîtrisée, offre de nombreuses ressources: on a remarqué que les noms (et particulièrement les noms sujets) étaient plus représentatifs du thème d’un document que les verbes ou les adjectifs. En reconnaissant la catégorie grammaticale et la fonction d’un mot, un programme informatique permet de pondérer les mots non vides selon ces critères. De plus, l’identification des terminaisons des mots variables, couplée à la consultation d’un dictionnaire de la langue, permet de reconnaître sous la diversité des formes l’appartenance à un même mot type.D’autres chercheurs s’attaquent à la faiblesse principale de l’indexation automatique: la sélection de mots isolés. La reconnaissance des syntagmes nominaux (moteur d’alternateur, indexation automatique) et de leur fonction syntaxique permet une recherche beaucoup plus précise. L’équipe lyonnaise SYDO (G. Bouché et M. Le Guern) travaille à affiner cette méthode prometteuse.En intégrant un réseau de relations sémantiques aux systèmes d’analyse automatique du contenu, on peut aller encore plus loin, et fournir à l’ordinateur un semblant de connaissance des concepts et de leurs relations. Ces méthodes relèvent des systèmes experts, très en vogue depuis quelques années. Si, par exemple, on intègre à un logiciel un thesaurus (cf. L’indexation automatique ), on peut enrichir l’indexation en ajoutant aux termes retenus des termes équivalents ou plus généraux (exemple: vérificationcontrôle, surveillance).Ces systèmes, dont plusieurs ont fait leur preuve, restent coûteux en temps machine. Il est probable qu’ils ne rivaliseront jamais avec la finesse de l’indexation humaine. Mais ils peuvent en être un complément ou même un substitut. Les années 1990 ont permis le développement de tels systèmes, parallèlement à la traduction assistée par ordinateur.Signalons le foisonnement des logiciels commercialisés, SPIRIT (méthode statistique et linguistique), ALEXIS (méthode linguistique et sémantique), SINTEX (sélection automatique de descripteurs soumise au contrôle d’un indexeur), BASIS, TEXTO, SUPERDOC et leurs diverses versions.
indexation [ ɛ̃dɛksasjɔ̃ ] n. f.• 1948; autre sens 1845; de index1 ♦ Révision d'un prix ou d'une convention en fonction des variations d'une grandeur économique, d'un indice pris comme référence. Indexation des loyers sur l'indice à la construction. Indexation d'une pension alimentaire, des salaires (cf. Échelle mobile). — Dr. comm. Clause d'une convention à échéance différée, en vertu de laquelle une somme pourra être modifiée en fonction d'un indice économique ou monétaire. Indexation d'un emprunt.2 ♦ Action d'indexer (2o). ⇒ classement. Indexation automatique de documents grâce aux mots-clés.⊗ CONTR. Désindexation.
● indexation nom féminin ou indexage nom masculin Action d'indexer ; fait d'être indexé. Variation automatique, au cours du temps et en fonction d'un indice déterminé, du montant d'une dette (d'un loyer, d'un salaire, d'un prix).indexationn. f. Action d'indexer.⇒INDEXATION, subst. fém.Action d'indexer.A. — [Correspond à indexer B]1. DOCUMENTOL. ,,Le fait de dresser un répertoire ou une liste, généralement alphabétique, des sujets traités, des noms cités dans un ouvrage, suivis des références aux pages, aux paragraphes`` (ROLLAND-COUL. 1969).2. LEXICOL. Indexation d'un corpus. Fait d'établir un relevé complet du vocabulaire, c'est-à-dire un inventaire de toutes les formes ou des unités lexicales qui figurent dans un énoncé ou un ensemble d'énoncés déterminé(s) (d'apr. D.D.L. 1976). Le premier problème documentaire qui se pose pour le traitement des titres est celui de la confection du « dictionnaire des mots vides » ou « dictionnaire négatif », c'est-à-dire de la liste des mots qui ne seront pas retenus par l'ordinateur pour l'indexation (FUNCK, MOUREAU, B. Bibl. Fr., t. 11, 1968, p. 340).B. — [Correspond à indexer C] ÉCON. ,,Action consistant à lier la valeur d'un capital ou d'un revenu à l'évolution d'une variable de référence (prix, production, productivité, par exemple)`` (BERN.-COLLI Extr. 1976). Indexation d'un emprunt sur le prix de l'or, indexation des traitements sur le coût de la vie. Originellement les techniques d'indexation ont été liées à la nécessité de protéger les titulaires d'un capital ou d'un revenu contre la dépréciation résultant de l'érosion monétaire, à travers le mécanisme de l'inflation (BERN.-COLLI Extr. 1976) :• ... le monde agricole se bat essentiellement pour le retour à l'indexation. D'ailleurs, les meetings aboutissent, le 3 mars 1960, à la promulgation du décret relatif aux conditions d'établissement des prix agricoles : rétablissement d'une indexation automatique des prix de certains produits.DEBATISSE, Révol. silenc., 1963, p. 177.REM. Indexage, subst. masc., rare, synon. (supra A). L'indexage peut aller de la simple notice indicative ne contenant que le titre du document et les indications bibliographiques, jusqu'à la notice informative, comportant un résumé analytique plus ou moins important (M. VAN DIJK, Coût de la recherche documentaire ds Rev. Int. Doc., vol. 30, 1963, n° 4, p. 143). On remarquera l'astuce du découpage ou de l'indexage de la grille, ce qui donne une sélection automatique des fiches et facilite grandement leur recherche (BERNATÉNÉ, Comment concevoir docum., 1964, p. 86).Prononc. : [ ], [-de-]. Étymol. et Hist. 1948 « classement sous forme d'index » (Nouv. Lar. univ.); 1955 écon. (R. BARRE, Écon. pol., P.U.F., t. 1, p. 310 ds QUEM. DDL t. 20). Dér. de indexer; suff. -(a)tion.indexation [ɛ̃dɛksɑsjɔ̃] n. f.ÉTYM. Mil. XXe (in Larousse, 1948, sens 2; aussi indexage); de indexer; proposé dans Richard de Radonvilliers (1845) pour « mise à l'index ».❖1 (1955, in T. L. F.). Action d'indexer (1.). Dr. comm. Clause d'une convention à échéance différée, en vertu de laquelle une somme pourra être modifiée en fonction d'un indice économique ou monétaire. || L'indexation d'un emprunt sur la valeur de l'or. — Dr. fin. Garantie assurée, lors de l'émission d'un emprunt, contre la dépréciation de la monnaie.2 Action d'indexer (2.). || L'indexation est la méthode la plus utilisée d'analyse documentaire. || « L'indexation des documents, qui est réalisée à l'aide d'un lexique constamment remis à jour » (Documentaliste, no 1, janv.-févr. 1984, p. 5). || « L'indexation par mots clés rend la recherche extrêmement aisée » (Livres-hebdo, no 42, 17 oct. 1983, p. 69).1 Dans les ouvrages à rédaction suivie, le XVIIIe, siècle accumule à peu près tous les procédés connus, en particulier les notes marginales médiévales qui subsistent soit pour résumer les paragraphes, soit pour introduire les références qui toutefois sont déjà le plus fréquemment en bas de page. Les index alphabétiques en fin de volume, déjà courants au XVIe siècle, sont presque constants.L'évolution la plus intéressante, de notre point de vue, est celle qui se situe à l'opposé de l'indexation alphabétique et qui concerne le contenu global de l'ouvrage.A. Leroi-Gourhan, le Geste et la Parole, t. II, p. 71.2 Lors de l'indexation, il s'agit de dégager les concepts du texte du document et de les exprimer à l'aide des termes du langage retenu : mots clefs, descripteurs ou indices d'une classification. Le niveau de l'indexation est plus ou moins fin selon la complexité du langage utilisé et selon le but poursuivi dans le cadre du système (indexation en vue d'une diffusion sélective ou en vue de la recherche rétrospective). Le terme d'indexation est souvent opposé à celui d'extraction. Il s'agit de deux variantes d'une même méthode d'analyse.Jacques Chaumier, les Techniques documentaires, p. 15.❖COMP. Surindexation.
], [-de-]. Étymol. et Hist. 1948 « classement sous forme d'index » (Nouv. Lar. univ.); 1955 écon. (R. BARRE, Écon. pol., P.U.F., t. 1, p. 310 ds QUEM. DDL t. 20). Dér. de indexer; suff. -(a)tion.indexation [ɛ̃dɛksɑsjɔ̃] n. f.ÉTYM. Mil. XXe (in Larousse, 1948, sens 2; aussi indexage); de indexer; proposé dans Richard de Radonvilliers (1845) pour « mise à l'index ».❖1 (1955, in T. L. F.). Action d'indexer (1.). Dr. comm. Clause d'une convention à échéance différée, en vertu de laquelle une somme pourra être modifiée en fonction d'un indice économique ou monétaire. || L'indexation d'un emprunt sur la valeur de l'or. — Dr. fin. Garantie assurée, lors de l'émission d'un emprunt, contre la dépréciation de la monnaie.2 Action d'indexer (2.). || L'indexation est la méthode la plus utilisée d'analyse documentaire. || « L'indexation des documents, qui est réalisée à l'aide d'un lexique constamment remis à jour » (Documentaliste, no 1, janv.-févr. 1984, p. 5). || « L'indexation par mots clés rend la recherche extrêmement aisée » (Livres-hebdo, no 42, 17 oct. 1983, p. 69).1 Dans les ouvrages à rédaction suivie, le XVIIIe, siècle accumule à peu près tous les procédés connus, en particulier les notes marginales médiévales qui subsistent soit pour résumer les paragraphes, soit pour introduire les références qui toutefois sont déjà le plus fréquemment en bas de page. Les index alphabétiques en fin de volume, déjà courants au XVIe siècle, sont presque constants.L'évolution la plus intéressante, de notre point de vue, est celle qui se situe à l'opposé de l'indexation alphabétique et qui concerne le contenu global de l'ouvrage.A. Leroi-Gourhan, le Geste et la Parole, t. II, p. 71.2 Lors de l'indexation, il s'agit de dégager les concepts du texte du document et de les exprimer à l'aide des termes du langage retenu : mots clefs, descripteurs ou indices d'une classification. Le niveau de l'indexation est plus ou moins fin selon la complexité du langage utilisé et selon le but poursuivi dans le cadre du système (indexation en vue d'une diffusion sélective ou en vue de la recherche rétrospective). Le terme d'indexation est souvent opposé à celui d'extraction. Il s'agit de deux variantes d'une même méthode d'analyse.Jacques Chaumier, les Techniques documentaires, p. 15.❖COMP. Surindexation.
Encyclopédie Universelle. 2012.